Een kijkje in het brein van Artificiële Intelligentie
In maart 2016 versloeg Google’s computerprogramma AlphaGo de wereldkampioen Lee Sedol in het bordpsel Go. De wereld van artificiële intelligentie daverde op zijn grondvesten. Go is namelijk een van de moeilijkste bekende bordspelen, vele honderden keren moeilijker voor een computer dan bijvoorbeeld schaken. Bijna niemand had verwacht dat deze mijlpaal bereikt zou worden voor 2020.
Hoe is Google er dan in geslaagd om de wereldkampioen te verslaan? Het antwoord ligt bij dezelfde systemen die meer en meer ons dagelijks leven rechtstreeks en onrechtstreeks beïnvloeden: neurale netwerken. Een neuraal netwerk is een model dat ruwweg gebaseerd is op hoe menselijke hersens werken: een groep hersencellen (neuronen) werkt samen door signalen naar elkaar door te sturen om zo een uitvoersignaal te genereren.
Wat neurale netwerken speciaal maakt is het feit dat ze kunnen leren uit hun fouten. Zo werd AlphaGo getraind door duizenden wedstrijden tegen zichzelf te spelen, en zo te leren welke strategie het meest succesvol was. Eén van de wetenschappers achter AlphaGo, Thore Graepel, vat het als volgt samen:
“Hoewel we de machine geprogrammeerd hebben om te spelen, hebben we geen idee wat ze gaat doen. […] Wij maken enkel de datasets en het trainingsalgoritme. Maar de zetten die ze dan maakt zijn buiten onze controle – en veel beter dan wat wij, als Go spelers, zouden kunnen verzinnen.”
Deze uitspraak duidt zowel de meest intrigerende eigenschap als één van de grootste problemen aan van neurale netwerken: ze zijn black boxes. Dit betekent dat niemand, zelfs niet de ontwerper van het neuraal netwerk, kan zien of begrijpen hoe het netwerk “denkt”: wij geven het gewoon een vraag, en het netwerk geeft een antwoord terug.
Deze eigenschap lijkt op het eerste zicht misschien indrukwekkend, maar als we er wat langer over nadenken merken we dat het ook een zeer gevaarlijke eigenschap is. Stel bijvoorbeeld dat we een neuraal netwerk willen trainen om een auto te besturen, om zo een zelfrijdende auto te ontwikkelen. Hoe weten we ooit dat het netwerk altijd de juiste beslissing zal maken, en niet volledig zal crashen als er bijvoorbeeld een slecht verlichte fietser passeert?
Gelukkig bestaan er naast neurale netwerken nog andere modellen die uit ervaring kunnen leren. Bij veel van deze technieken kunnen we wel inzicht krijgen in wat ze geleerd hebben. Zo bestaan er bijvoorbeeld technieken die een aantal als-dan regels aanleren, bv. “Als de auto voor ons dichtbij komt, dan moeten we remmen”. Zulke modellen kunnen we gemakkelijk interpreteren door gewoon de als-dan regels af te lezen.
Het probleem hier is dat zulke interpreteerbare modellen op grote problemen veel minder goed presteren dan neurale netwerken. Technieken gebaseerd op als-dan regels zouden bijvoorbeeld nooit in staat zijn geweest om de wereldkampioen Go te verslaan. We moeten dus een keuze maken: sterke prestaties, of een interpreteerbaar model.
In deze thesis introduceren we een nieuwe techniek om deze keuze te verzachten. We doen dit door middel van distillatie. Dit betekent dat we een neuraal netwerk eerst een taak aanleren, om vervolgens de kennis van het neuraal netwerk over te brengen naar een meer interpreteerbaar model.
We kunnen het neuraal netwerk hier beschouwen als een leerkracht, en het interpreteerbaar model als een leerling. De leerling kan uit zichzelf een probleem moeilijk oplossen, maar met de hulp van een leerkracht lukt het wel. Deze aanpak laat ons toe om interpreteerbare modellen problemen te laten oplossen die ze op zichzelf niet zouden aankunnen. Zo combineren we het beste van beide werelden: sterke prestaties en een interpreteerbaar model.
We probeerden onze techniek uit op een klassiek testprobleem: het balanceren van een paal. In dit probleem vertrekken we van een simulatie van een paal die rechtop staat en onderaan op één punt vastgemaakt is. Het doel is om de paal te balanceren door ze naar links of naar rechts te bewegen. Dit is een voorbeeld van een probleem dat een neuraal netwerk gemakkelijk kan oplossen, maar een model gebaseerd op als-dan regels niet.
Het experiment loopt als volgt: eerst trainen we een neuraal netwerk met 128 neuronen om de paal te balanceren. Vervolgens testen we ook of een model met 30 als-dan regels in staat is om het probleem op te lossen. Ten slotte distilleren we de kennis van het neuraal netwerk in een nieuw als-dan model. Deze als-dan regels hebben hier bijvoorbeeld de vorm: “Als de paal overwegend naar links helt, en aan het vallen is, duw dan de paal naar rechts.”
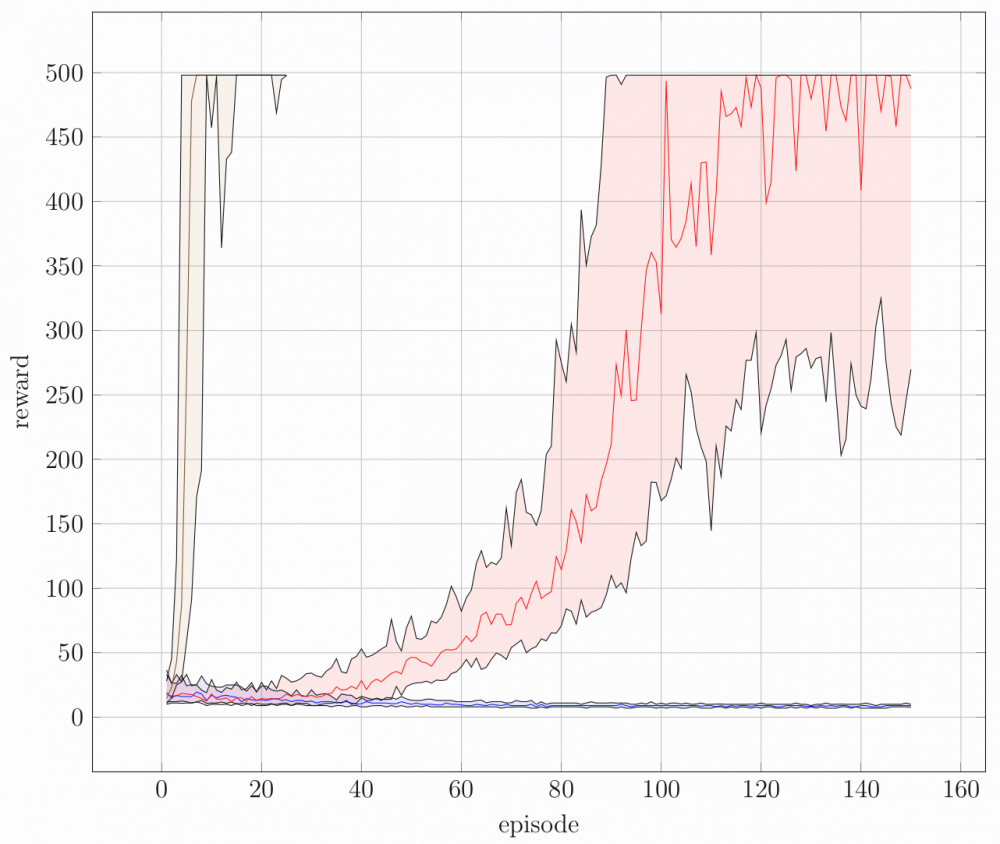
De resultaten van het experiment worden weergegeven in de figuur. "Episode" betekent de "poging", iedere keer dat de paal naar beneden valt begint een nieuwe episode. De modellen kregen elk 150 pogingen. "Reward" is de prestatie van het model, hoe langer de paal omhoog blijft, hoe hoger de reward. Iedere curve geeft dus weer hoe goed een model presteert in functie van de tijd. De rode, blauwe en bruine curve komen respectievelijk overeen met het neuraal netwerk, het model met 30 als-dan regels, en het gedistilleerde model met 5 als-dan regels. We zien dat de blauwe curve beneden blijft, wat weergeeft dat het model met 30 als-dan regels niet in staat is om het probleem op te lossen. In tegenstelling tot de blauwe curve, zien we de bruine curve wel zeer snel stijgen. Dit betekent dat een model met slechts 5 als-dan regels via distillatie het probleem vrijwel meteen kan oplossen.
Hoewel de techniek hier slechts werd toegepast op een speelgoedvoorbeeld, zijn de resultaten al zeer veelbelovend. Er bestaat tot nu toe namelijk nog geen techniek die een neuraal netwerk op dit klassiek probleem op zo’n compacte manier kan samenvatten. De volgende stap is nu om hetzelfde idee te verfijnen en uit te breiden. We kunnen het dan toepassen op zwaardere en zwaardere problemen, totdat we uiteindelijk misschien toch een kijkje kunnen nemen in het bovenmenselijke brein van AlphaGo.