
Computers met artificiële intelligentie beschrijven museumcollecties
Je hebt vast al eens een foto getrokken met je smartphone. Maar heb je ook al eens in je fotobibliotheek gezocht naar foto’s met de zoekfunctie? Als je in de zoekbalk van Google Photos of Apple Photos 'honden' intikt, dan wordt in je fotobibliotheek gezocht naar alle foto’s waar een hond op staat. Dit is een techniek die beeldherkenning genoemd wordt en die ons helpt bij het organiseren en zoeken van foto’s en video’s.
Probleemstelling
De Vlaamse musea bewaren ook veel digitale beelden. Het ontbreekt hen echter aan tijd en mankracht om die beelden te voorzien van metadata of tags. Nochtans is het zoeken of vinden van die digitale beelden moeilijk als je bij de zoekactie geen gebruik kunt maken van trefwoorden. Dit verschilt van digitale tekstbestanden, waarbij op basis van full text search bestanden teruggevonden kunnen worden. Het gevolg is dat slechts een deel van de beelden beschreven werden en dat musea over een grote hoeveelheid beelden beschikken die niet gebruikt of ontsloten kunnen worden.
Bij de beelden die wel beschreven werden, zijn de beschrijvingen meestal beperkt tot formele en administratieve gegevens die nodig zijn voor het beheer van de collectiestukken. Registratie is immers tijdrovend werk dat door domeinexperten gedaan wordt. Voor het beschrijven van inhoudelijke informatie zoals afgebeelde personen of objecten, emoties en sfeer ontbreekt het de musea aan tijd en personeel, terwijl dat net de informatie is die interessant is voor het publiek en onderzoek.
In de bachelorproef werd daarom onderzocht of beeldherkenning de museummedewerkers kunnen bijstaan in het beschrijven van hun collecties. Beeldherkenningssoftware is er de laatste jaren enorm op vooruitgegaan en wordt ook steeds eenvoudiger in gebruik.
Computer Vision
Computer Vision is het onderzoeksveld waarin technieken ontwikkeld worden om computers te helpen bij het zien en begrijpen van de inhoud van digitale beelden zoals foto’s en video’s. Het is een deelgebied van Artificiële Intelligentie (AI). Computer Vision wordt met succes toegepast voor een breed scala van uitdagingen zoals inspectie van machines, geautomatiseerde kassa-afrekeningen in de retail, medische beeldvorming, bewaking en politieonderzoek en het assisteren van mensen bij het identificeren van de inhoud van een foto of video.
Beeldherkenning is een techniek binnen computer vision. Hiervoor wordt de AI-toepassing een model aangeleerd dat bestaat uit het geheel van concepten die het moet herkennen. Dat wordt gedaan aan de hand van een trainingset. Als je wil dat het een bus herkent, dan bestaat de trainingsset uit verschillende voorbeelden van een bus, maar ook van wat een bus niet is. Wanneer, na de training, het model nieuwe beelden ziet, zou het moeten kunnen zeggen of het afgebeelde object een bus is of niet. Als de AI-toepassing nog andere objecten moet herkennen, dan moet het nieuwe trainingsbeelden krijgen, bijvoorbeeld foto’s van een fiets om te leren wat een fiets is.
Google, Amazon, Microsoft en Clarifai bieden beeldherkenningsdiensten aan die het mogelijk maken om Computer Vision te gebruiken, zonder dat je een expert in AI moet zijn. Deze diensten zijn al getraind, waardoor het niet nodig is om zelf trainingsbeelden te voorzien en modellen te trainen. Daarnaast kan je ook zelf in de meeste van deze diensten eenvoudig een eigen model creëren.
Case study
Beeldherkenningsdiensten zijn doorgaans getraind met hedendaagse beelden, waaronder de foto’s die we dagelijks maken en opslaan in hun cloudinfrastructuur. We wisten daarom niet hoe goed deze diensten zijn in het beschrijven van historische foto’s. Dit werd onderzocht aan de hand van een case study met historische foto’s van het Gentse museum Huis van Alijn. We testten ook uit hoe eenvoudig het is om de beeldherkenningsdiensten te gebruiken en om eigen modellen te bouwen. Kunnen museummedewerkers zonder IT-kennis hier zelf mee aan de slag?
Huis van Alijn heeft een grote fotocollectie over het dagelijkse leven in België in de twintigste eeuw. Om de foto’s te kunnen ontsluiten of te doorzoeken, heeft het museum nood aan gegevens die een idee geven van wat er op het beeld staat. De foto’s worden door het museum ingedeeld in thema’s (bv. huwelijk, vakantie en speelgoed) en decennia (bv. 50s, 60s). Het zou voor het museum een enorme hulp zijn als via beeldherkenning de foto’s voorzien worden van beschrijvingen en ingedeeld in het juiste thema en periode.
Aan Huis van Alijn werd voorgesteld om drie cases te onderzoeken:
- Het automatisch beschrijven van iedere foto - in de vorm van tags - door het ingebouwde model van de beeldherkenningsdienst. De tags werden vergeleken met de bestaande beschrijvingen van de museumregistratoren.
- Het classificeren van de foto’s in de thema’s van Huis van Alijn. Hiervoor werd een eigen model gecreëerd en werd de beeldherkenningsdienst getraind.
- Het indelen van de foto’s in het decennium waarin ze gemaakt werden. Ook hiervoor werd een custom model ontwikkeld en werd de CV API getraind.
Resultaten

We stelden vast dat de beeldherkenningsdienst eenvoudig in gebruik is en geschikt om twee van de drie cases goed uit te voeren. Ongeveer 70% van de tags die het ingebouwde model van beeldherkenningsdienst aanleverde, waren correct. Het scoorde vooral goed op universele thema's, zoals geboorte, huwelijk en vakantie. We merkten ook dat heel andere termen gegeven werden dan gangbaar zijn in de registratiepraktijk, zoals tags die de sfeer, emoties en kleur van de foto's weergeven. Bij foto's van lokale tradities, zoals Sinterklaas, werd ervaren dat het model in de VS gemaakt was. Hierop scoorde het ondermaats.
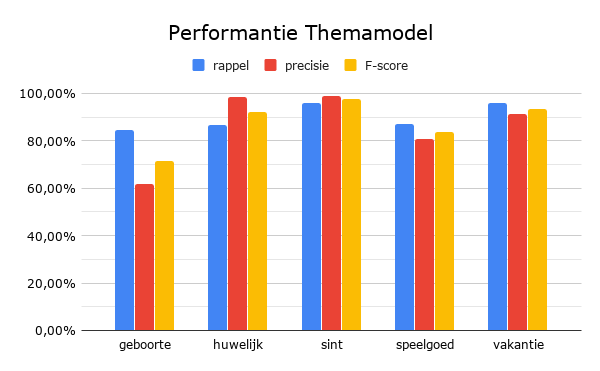
Voor het classificeren van de foto’s per thema volstond het ingebouwde model niet. Het zelfgemaakte Themamodel, dat de foto's moest indelen volgens thema, deed dit wel goed (bijna 90% correctheid). Voor het indelen van de foto's volgens decennium was de trainingset te beperkt. Een pijnpunt tijdens het trainen was immers de kleine en ongelijke set beelden. Dat is echter een gangbaar fenomeen in erfgoedcollecties.
Conclusie
Museumregistratoren hoeven nog niet voor hun job te vrezen. Vooralsnog zijn ze preciezer en correcter dan beeldherkenningsdiensten. Niettemin kunnen de diensten een goede aanvulling zijn en het werk van de registrator verlichten. De kracht van de beeldherkenningsdiensten ligt vooral in hun snelheid en het aanleveren van andere soort termen, zoals beschrijven van sfeer.







