
Interpretatie en modellering van multi instrumentele analytische data met Deep Learning
De moderne analytische toestellen en technieken zorgen ervoor dat bedrijven en onderzoekers steeds meer te maken krijgen met een grote kwantiteit aan data. De dataset wordt daarbij ook steeds uitdagender om mee te werken. Dit is ook het geval bij de afdeling professionele textielverzorging van het bedrijf Christeyns NV te Gent. De textielstalen worden er met verschillende analytische toestellen zowel kwalitatief als kwantitatief geanalyseerd. Door het steeds groter wordend aantal geanalyseerde textielstalen en de grote hoeveelheid gegevens die per staal verkregen worden, werd bij de R&D-afdeling van de textielverzorging al een behoorlijk grote dataset met gegevens verworven.
De dataset bevat gegevens afkomstig van drie verschillende analysetechnieken namelijk witheidsmetingen met een spectrofotometer, Fourier-transformatie infraroodspectroscopie (FTIR) en high-performance liquid chromatography (HPLC). Er werd onderzocht hoe het best kan worden omgegaan met deze dataset en welke technieken het meest geschikt zijn voor het verkrijgen van nieuwe inzichten in de beschikbare data. Het hoofddoel is uiteindelijk om correlaties tussen de gegevens van de drie verschillende analysetoestellen op te sporen.
Na een theoretische studie over verschillende technieken voor de verwerking van de beschikbare dataset, werd uiteindelijk toegelegd op de techniek Deep Learning. Deep Learning is een onderdeel van Artificiële Intelligentie, wat een overkoepelende term is voor elke techniek waarmee computers menselijk gedrag nabootsen. Bij Deep Learning leert de logaritme zelf door input van de omgeving op te slaan, patronen erin te herkennen en deze vervolgens toe te passen met oog op succes. Dit kan het best uitgelegd worden aan de hand van het voorbeeld van AlphaZero. AlphaZero is een schaakcomputer die met behulp van Deep Learning zichzelf leerde schaken. Na slechts negen uur schaken tegen zichzelf kon AlphaZero tien keer achter elkaar winnen tegen een andere schaakcomputer Stockfish. Dit is zeer opmerkelijk aangezien experts al tientallen jaren bezig zijn om alle strategieën van het schaken in Stockfish te programmeren. Met behulp van Deep Learning wordt hetzelfde niveau behaald in slechts vier uur, zonder tussenkomst van de mens.
Deep learning is een algoritme dat gebaseerd is op de werking van onze hersenen. Er wordt bij deze techniek gebruikgemaakt van een zogenaamd computer neuraal netwerk, waarbij een groot aantal met elkaar verbonden neuronen in verschillende lagen gerangschikt zijn. Aan de ene kant is er de ingangslaag, waar de informatie binnenkomt, bijvoorbeeld een positie op een schaakbord. Aan de andere kant is er de uitgangslaag, hier komt de beslissing van het neuraal netwerk uit, bijvoorbeeld de beste zet op het schaakbord. Daartussen bevinden zich nog lagen. Deze worden de verborgen lagen genoemd. (Figuur 1) Alle neuronen in een neuraal netwerk zijn met elkaar verbonden met een verschillende sterkte. De werking van zo een neuraal netwerk kan worden uitgelegd aan de hand van een tweede voorbeeld, namelijk het herkennen van handgeschreven letters. Aan de ingangslaag is elk neuron de grijswaarde van een pixel van de geschreven letter. De uitgangslaag bestaat uit 26 neuronen die de letters van het alfabet voorstellen. Vanaf de ingangslaag geven de neuronen laag per laag hun informatie door. Door de verschillende sterktes van de verbindingen wordt er uiteindelijk een bepaalde voorspelling bekomen bij de uitgangslaag. Bij een niet getraind neuraal netwerk zijn de sterktes tussen de verbindingen een initiële gok, waardoor de kans groot is dat de voorspelling nog fout zal zijn. Het neuraal netwerk wordt getraind door telkens aan te geven dat het fout is, zodat het zich in de toekomst kan corrigeren. Wanneer het neuraal netwerk een verkeerde letter voorspelt, worden de verbindingen die voor die voorspelling gezocht hebben verzwakt. Wanneer er wel een juiste letter voorspeld wordt dan worden de verbindingen die daarvoor gezorgd hebben versterkt. Op die manier leert het algoritme om de juiste voorspelling te maken.
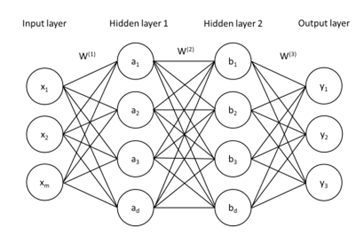
Figuur 1: Schematische voorstelling van een neuraal netwerk met twee verborgen lagen.
Neurale netwerken worden tegenwoordig in zeer veel domeinen ingezet. Zo wordt Deep Learning gebruikt bij het vertalen van teksten met Google Translate, bij de ontwikkeling van zelfrijdende auto’s of bij het praten tegen Siri of Alexa. Ook bij steeds meer bedrijven wordt Deep Learning ingezet voor het in kaart brengen van data en bedrijfsprocessen.
In dit onderzoek werd Deep Learning gebruikt voor het verkrijgen van nieuwe informatie uit de beschikbare dataset en het zoeken van correlaties in de gegevens van de verschillende analysetoestellen. Dit gebeurt door het uitvoeren van verschillende classificaties en regressies. Enkele voorbeelden hiervan zijn de classificatie van de stalen naargelang de witheid van het textiel met behulp van gegevens uit HPLC analysen en de voorspelling van concentratie aan Diaminostilbeen en Distyrylbifenyl type optische witmakers op het textiel aan de hand van HPLC-data.
Wanneer Deep Learning gebruik werd voor classificaties en regressies met gegevens van slechts één analysetoestel, namelijk een Konica Minolta CM-3600 reflectantiespectrofotometer, werden zeer nauwkeurige voorspellingen behaald. Zo kon de witheidsindex in Ganz van textiel voorspeld worden uit het ruwe reflectie-spectrum met een procentuele fout van slechts 1 %. Hierdoor wordt de berekening van de witheidgraad in Ganz overbodig.
Verder werden de gegevens van de reflectantiespectrometrie gecombineerd met de concentratiebepaling van optische witmakers aanwezig op het textiel (HPLC). Op deze manier kan er voor een gegeven reflectantiespectrum een correlatie gemaakt worden met het gehalte aan optisch wit aanwezig. Op basis van de bestaande resultatensets werd een voorspellingsnauwkeurigheid behaald van 20%. De resultaten zijn hier minder nauwkeurig door een beperktere dataset, concentratievariatie binnen één stuk textiel en de logaritmische respons van de opbouw van optisch wit en de reflectantiewaarden. Hiernaast wordt duidelijk dat een optimalisatie van de dataset vooraf een zeer belangrijke stap is in het proces.
Dit onderzoek toont aan dat Deep Learning een veelbelovende techniek kan zijn voor de verwerking van de dataset en het vinden van correlaties tussen de gegevens van de drie verschillende textiel analysemethoden. Deze thesis is echter nog maar het begin van het onderzoek en het is duidelijk dat met deze techniek nog veel verder kan gegaan worden. Het is gebleken dat het met een goede en slimme analyse door Deep Learning mogelijk is om de toenemende hoeveelheid data werkelijk te benutten.







