
Is taal de sleutel bij het decoderen van hersengolven?
Brein-Computer Interfaces en Machine Learning
Een Brein-Computer Interface (BCI) is een apparaat dat de digitalisatie van het brein toelaat. De BCI-pijplijn werkt als volgt (zie Figuur 1). Eerst wordt hersenactiviteit gemeten, dit kan aan de hand van een verscheidenheid aan modaliteiten. Elektro-encefalografie (EEG) is daar een van. EEG bestaat uit metingen van de elektrische breinpotentialen op de hoofdhuid (zie Figuur 2). Zo’n metingen kunnen aan de hand van Machine Learning (ML) gedecodeerd worden, wat resulteert in een reeks intenties. Tenslotte worden deze intenties gebruikt om een bepaald apparaat aan te sturen. Recente vooruitgang in onderzoek naar BCI’s heeft klinische toepassingen mogelijk gemaakt, zoals het voorspellen van epileptische aanvallen in een vroeg stadium en breingestuurde protheses, maar ook alledaagse toepassingen zoals intentieherkenning voor smart-living en voertuig- en robotbesturing. Afgezien enkele zeer specifieke gevallen liggen efficiënte en betrouwbare BCI's echter nog ver weg. De ML-methoden die BCI's toepassen om hersenactiviteit te interpreteren moeten nog tal van uitdagingen overwinnen. Data schaarste en variatie in hersenactiviteit, zowel tussen personen als bij een enkele persoon, maken het ontwerpen van BCI’s een complexe zaak. Soortgelijke problemen zijn onderzocht in andere onderzoeksgebieden, waarbij oplossingen zijn gevonden die als inspiratie kunnen dienen voor nieuwe ML-methoden voor BCI’s. Dit onderzoek gaat nog een stap verder. Hier wordt niet enkel gebruikt gemaakt van een ML-model uit een ander domein maar ook van wat dat model reeds geleerd heeft in dat domein.
Figuur 1: BCI-pijplijn.
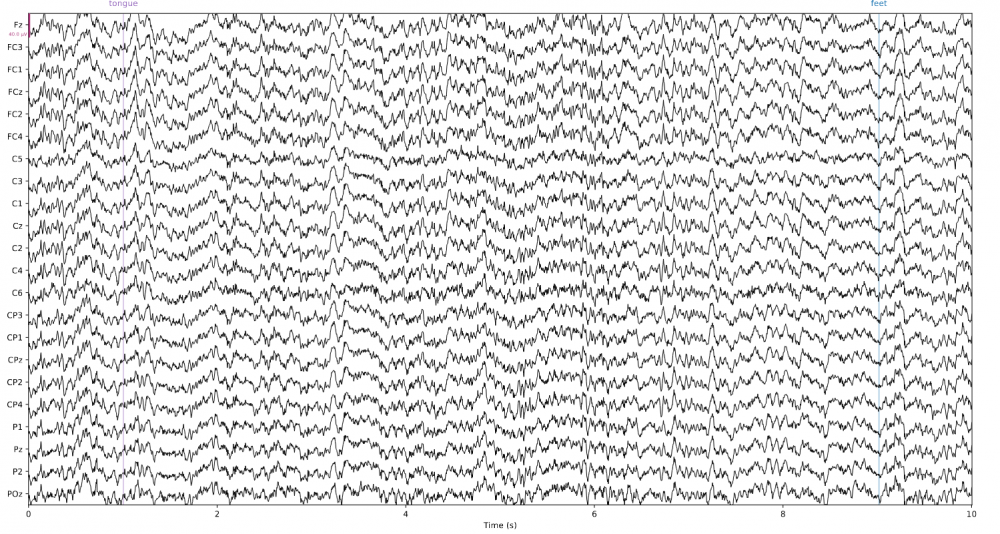
Figuur 2: De eerste 10 seconden van een voorbeeld EEG-opname. De horizontale as toont de tijd in seconden, de verticale as toont de EEG-electroden. Intenties worden aangeduid in gekleurde verticale lijnen.
Kennisoverdracht
Het decoderen van hersenactiviteit wordt gekenmerkt door een cruciaal probleem: metingen van hersenactiviteit kunnen aanzienlijk verschillen, tussen personen en zelfs voor dezelfde persoon. Om nauwkeurige BCI's te ontwerpen moeten ML-methoden worden gevonden die algemene patronen kunnen leren die op elke persoon van toepassing zijn. Dit aspect van kennisoverdracht heeft in BCI’s altijd al de vorm aangenomen van een ML-model dat eerst leert uit metingen van een aantal personen of verschillende metingen van een bepaald persoon en vervolgens verder leert op de metingen van de persoon die de BCI zal gebruiken. In sommige gevallen leren ML modellen eerst uit data van een geheel verschillend domein. Een recent voorbeeld is een ML model dat eerst leert om foto’s te classificeren aan de hand van een gigantische foto database. Door metingen van hersenactiviteit als foto’s voor te stellen kan zo’n model vervolgens verder leren hersenactiviteit te classificeren, wat resulteert in een relatief accuraat BCI-model. De toegevoegde waarde van deze manier van werken is dat schaarste van data een kleiner probleem is in het domein van foto’s. Met dit in het achterhoofd werkt dit onderzoek aan een gelijkaardige methode maar in plaats van foto’s wordt taal gebruikt. Een samenwerking tussen Facebook en Google resulteerde onlangs in een publicatie waarin beweerd wordt dat enorme taalmodellen die getraind worden op enorme taal databases gezien kunnen worden als algemene computationele modellen. Een aantal evaluaties van een gekend taalmodel in een aantal domeinen niet gerelateerd aan taal toonden dat dit taalmodel, zonder iets van deze domeinen geleerd te hebben, relatief goed presteert. Dit wil zeggen dat er hoogstwaarschijnlijk patronen te vinden zijn in taal die algemeen toepasbaar zijn in domeinen verschillend van taal. In dit onderzoek wordt nagegaan of dit geldt voor EEG.
Taalmodellen voor het decoderen van EEG
Expliciet leest de onderzoeksvraag van dit onderzoek als volgt: “Hoe en in welke mate kan een op taal getraind ML-model overgaan op de classificatie van EEG en beïnvloedt de taaltraining de prestaties?” OpenAI’s GPT2 wordt in verschillende configuraties geëvalueerd op het classificeren van EEG. Een bestaande publieke motor imagery dataset wordt gebruikt. Motor imagery houdt in dat EEG opnames gemaakt worden van een persoon die zich inbeeldt bepaalde bewegingen uit te voeren. De taak van het ML model is om deze bewegingen uit de EEG-metingen te extraheren. Hoewel de finale performantie van GPT2 voor het classificeren van EEG de state-of-the-art niet verbetert, maakt een interessante observatie verder onderzoek de moeite waard. Er wordt namelijk waargenomen dat er een positief statistisch significant verschil is tussen de performantie van GPT2 als het voorgetraind is met taal ten opzichte van wanneer het dat niet is. Dit suggereert dat GPT2 uit de gigantische taaldatabase algemene patronen heeft geleerd die ook toepasbaar zijn in het domein van EEG. Aangezien zulke patronen momenteel relatief ongekend zijn introduceert dit onderzoek dus een nieuwe onderzoeksrichting. Met name, onderzoek dat modellen uit andere domeinen analyseert om zo algemene EEG-patronen te vinden. Daarbij versterkt dit onderzoek ook de claim van de wetenschappers bij Facebook en Google dat deze grote taalmodellen gezien kunnen worden als modellen die verder gaan dan taal en eerder doen aan algemene computatie.
Verder onderzoek
De eerstvolgende stap na dit onderzoek houdt in te gaan kijken of betere performantie verkregen kan worden door gebruik te maken van grotere datasets. Door de grootte en complexiteit van GPT2 is het altijd een mogelijkheid dat het teveel details in de EEG-opnames bekijkt. Het doel van ML is niet op de details te focussen maar de algemene trends te vinden. Door meer data ter beschikking te stellen kan het model geforceerd worden om te gaan veralgemenen en zo algemenere patronen te vinden. Tegelijkertijd kunnen ook de gevonden patronen geanalyseerd worden om zo inspiratie te vinden voor nieuwe BCI-modellen. Deze kunnen op hun beurt BCI’s en het leven van de mens verbeteren.
Projectdetails
De code die geschreven werd voor dit onderzoek is te vinden op GitHub (https://github.com/wulfdewolf/lpt-for-eeg). Een samenvatting van de resultaten van dit onderzoek is te vinden op Weights&Biases (https://wandb.ai/wulfdewolf/lpt-for-eeg/reports/Transfer-Learning-in-Br…). De infrastructuur en dienstverlening gebruikt in dit onderzoek werd voorzien door het VSC (Vlaams Supercomputer Centrum), gefinancierd door het FWO en de Vlaamse overheid.







