Kan je een computer leren grappig te zijn?
Artificiële intelligentie laat toe om steeds meer jobs te automatiseren. Dat leidt tot onzekerheid in een heel aantal sectoren. Creatieve jobs worden desalniettemin vaak als veilig aanzien. Stel u voor dat we Philippe Geubels zouden vervangen door een echte robot. Absurd! Wat als we u echter zeggen dat computers al in staat zijn om half zo vaak grappig te zijn als mensen?
Robotkomieken
We gebruiken computers tegenwoordig met grote regelmaat om mopjes en memes op te zoeken en uit te wisselen met vrienden. Elk van deze berichten wordt momenteel door mensen gemaakt. De vraag stelt zich of onze dagelijkse dosis internethumor ooit van de hand van een computer zou kunnen komen. Kan een robotkomiek dan ook gepersonaliseerde mopjes voor en over zijn gebruiker maken? En zijn die mopjes dan überhaupt wel grappig?
In deze thesis onderzochten we de mogelijkheid om met computers mopjes te genereren, en dit door middel van het automatisch analyseren van bestaande moppen. Er bestaan reeds enkele programma’s die één bepaald soort humor kunnen produceren, door bijvoorbeeld simpele woordspelingen te construeren of door te weten na welke zinnen het passend is om “That’s what she said!” uit te printen. De kennis over het gekozen type humor werd echter steeds door onderzoekers handmatig gemodelleerd. In ons onderzoek construeerden we echter een framework dat in staat is om uit een verzameling moppen te leren hoe het zelf soortgelijke grappen kan genereren. Met dat systeem genereerden we honderd moppen die vervolgens door honderden vrijwilligers werden beoordeeld. Het resultaat? De gegenereerde mopjes werden 11,4% van de tijd als grappig aanzien, terwijl de mopjes van vrijwilligers 22,6% van de tijd grappig werden bevonden.
Computationeel gevoel voor humor
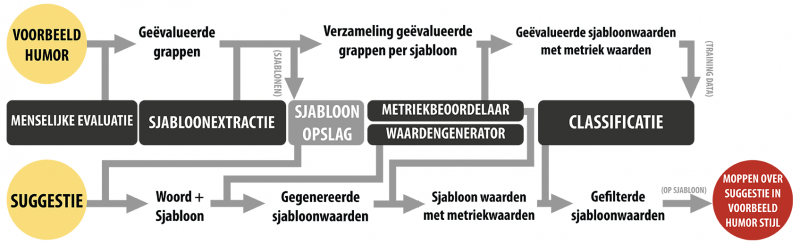
In het onderzoek leert het computerprogramma eerst scores toe te kennen aan mopjes. Daarna zoekt het de pareltjes in miljoenen willekeurige mopjes. Om het programma zulk gevoel voor humor te geven, laten we het eerst een grote verzameling tekstuele mopjes bekijken met bijbehorende beoordelingen. Leeralgoritmes werken echter liever met getallen dan met teksten van variabele lengte, zoals mopjes. Het programma detecteert daarom eerst grote gemeenschappelijke stukken tekst in de mopjes, en slaat die op als sjablonen. Een voorbeeld van een mogelijk sjabloon is “Ik hou van mijn X zoals ik hou van mijn Y: Z”. Een mogelijke woordinvulling voor X is dan “koffie”, voor Y “oorlog” en voor Z “koud”. Die stap zorgt ervoor dat de computer enkel nog met een vast aantal geselecteerde woorden per sjabloon moet werken.
Om het programma dan uit de geselecteerde woorden te laten leren, moet het die omzetten naar een reeks getallen. Daarvoor zijn maatstaven nodig: dat zijn functies die een of meerdere woorden transformeren naar een getal. In de thesis analyseren we verschillende humortheorieën en identificeren we zo een verzameling potentiële maatstaven. Een voorbeeld van een maatstaf is de frequentie waarmee een adjectief voorkomt om een substantief te beschrijven, om zo te benaderen hoe sterk bepaalde woorden bij elkaar horen. Deze maatstaven transformeren de geselecteerde woorden naar een verzameling getallen. Die getallen worden dan verwerkt met statistische technieken om te leren inschatten hoe goed een mop is. We verkregen het beste resultaat wanneer het programma de meest voorkomende beoordeling (1 tot 5 sterren) moest raden. Voor de voorbeeldmoppen kon het programma die taak de helft beter dan de vrijwilligers. Onze robotkomiek tracht op die manier dus een groot aantal toeschouwers hard te laten lachen, eerder dan alle toeschouwers een beetje te laten lachen.
JokeJudger
Ons systeem heeft nood aan een grote verzameling moppen als voorbeeldmoppen, liefst van hetzelfde type. We kozen voor grappige vergelijkingen in de vorm “I like my X like I like my Y: Z.” als type. Daarna creëerden we het platform JokeJudger.com, waar gebruikers zulke mopjes kunnen creëren en beoordelen. Dat platform gebruikten we zowel voor het verzamelen van de voorbeeldmoppen als om de gegenereerde moppen op het einde van het onderzoek te beoordelen. We verzamelden op dit platform een dataset van 203 gebruikers, 9 452 beoordelingen en 524 mopjes.
Automatische grappenselectie
Eens het algoritme getraind is op de verzamelde mopjes, is het in staat om uit grote hoeveelheden willekeurige moppen de beste te selecteren. Het programma genereert miljoenen mogelijke invullingen voor grappige vergelijkingen in de vorm “I like my X like I like my Y: Z”, waarbij X en Y substantieven zijn en Z een adjectief dat zowel bij X en Y past. Daarna selecteert het programma met zijn net aangeleerde gevoel voor humor de mopjes die volgens zijn inschattingsvermogen hoge scores zouden krijgen. Op die manier genereert het systeem dus goede moppen in een vorm gelijkaardig aan de gegeven voorbeeldmoppen.
Voordelen
Aangezien het systeem werkt voor meerdere soorten humor en automatisch nieuwe soorten moppen kan leren, generaliseert en verbetert onze methode het leeuwendeel van het bestaande onderzoek in computationele humor. Ook kan het systeem zich aanpassen aan specifieke gebruikers, door enkel hun beoordelingen te gebruiken in het leerproces en zo gepersonaliseerde moppen te genereren. Een ander voordeel is dat het programma in staat is te leren uit zijn eigen missers en voltreffers bij het publiek.
Bij het evalueren door honderden vrijwilligers vonden we dat grappige vergelijkingen gegenereerd door ons systeem 11,4% van de tijd als grappig werden ervaren. Mopjes afkomstig van onze vrijwilligers waren 22,6% van de tijd grappig. Gezien we een significant groot aantal beoordelingen (bijna tienduizend) verzameld hebben, kunnen we hieruit besluiten dat ons systeem al half zo vaak als grappig wordt ervaren als een doorsnee mens.
Dit jaar ziet u waarschijnlijk nog steeds Philippe Geubels – geen robot – weer op de planken. Maar aangezien de mopjes van het systeem in ons onderzoek al één kans op negen hebben om grappig te zijn, kunnen dergelijke systemen komieken wel helpen met het schrijven van hun teksten. Ook opent dit onderzoek de deur naar meer menselijke versies van Siri en Google Assistant, die hiermee net als echte vrienden kwinkslagen in hun antwoorden kunnen verwerken.
Bibliografie
- T. Agustini and R. Manurung. Automatic evaluation of punning riddle template extraction. In ICCC, pages 134–139, 2012.
- S. Attardo. The semantic foundations of cognitive theories of humor. 10:395–420, 01 1997.
- S. Attardo and V. Raskin. Script theory revis(it)ed: joke similarity and joke representation model. Humor, 4(3):293–347, 1991.
- C. Barnes, E. Shechtman, A. Finkelstein, and D. B. Goldman. Patchmatch: a randomized correspondence algorithm for structural image editing. ACM Trans. Graph., 28(3), 2009.
- C. Bauckhage. Insights into internet memes. In L. A. Adamic, R. A. Baeza-Yates, and S. Counts, editors, ICWSM. The AAAI Press, 2011.
- K. Binsted, B. Bergen, S. Coulson, A. Nijholt, O. Stock, C. Strapparava, G. Ritchie, R. Manurung, H. Pain, A. Waller, and D. O’Mara. Computational humor. IEEE Intelligent Systems, 21(2):59–69, 2006.
- K. Binsted and G. Ritchie. An implemented model of punning riddles. CoRR, abs/cmp-lg/9406022, 1994.
- L. Breiman. Random forests. Mach. Learn., 45(1):5–32, Oct. 2001.
- A. Chandrasekaran, D. Parikh, and M. Bansal. Punny captions: Witty wordplay in image descriptions. CoRR, abs/1704.08224, 2017.
- A. Chandrasekaran, A. K. Vijayakumar, S. Antol, M. Bansal, D. Batra, C. L. Zitnick, and D. Parikh. We are humor beings: Understanding and predicting visual humor. In CVPR, pages 4603–4612. IEEE Computer Society, 2016.
- A. Desoky. Jokestega: Automatic joke generation-based steganography methodology. Int. J. Secur. Netw., 7(3):148–160, Mar. 2012.
- J. Dunn. We put siri, alexa, google assistant, and cortana through a marathon of tests to see who’s winning the virtual assistant race - here’s what we found. http://uk.businessinsider.com/ siri-vs-google-assistant-cortana-alexa-2016-11, 2016. 69
- C. Fellbaum. WordNet: An Electronic Lexical Database. Bradford Books, 1998.
- W. N. Francis and H. Kucera. Brown corpus manual. Technical report, Department of Linguistics, Brown University, Providence, Rhode Island, US, 1979.
- S. Freud and J. Strachey. Jokes and Their Relation to the Unconscious. Complete Psychological Works of Sigmund Freud. Norton, 1960.
- S. Gella, C. Strapparava, and V. Nastase. Mapping wordnet domains, wordnet topics and wikipedia categories to generate multilingual domain specific resources. In N. C. C. Chair), K. Choukri, T. Declerck, H. Loftsson, B. Maegaard, J. Mariani, A. Moreno, J. Odijk, and S. Piperidis, editors, Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, may 2014. European Language Resources Association (ELRA).
- K. Goldberg, T. Roeder, D. Gupta, and C. Perkins. Eigentaste: A constant time collaborative filtering algorithm. Information Retrieval, 4(2):133–151, July 2001.
- B. Heate. Google is looking to creative writers and comedians to help humanize assistant. https://techcrunch.com/2016/10/10/google-laughsistant/, 2016.
- R. Hirst. Siri, echo and google home: are digital assistants the future of the office? https://www.theguardian.com/media-network/2016/nov/21/ siri-echo-google-home-digital-assistants-future-office, 2016.
- B. A. Hong and E. Ong. Automatically extracting word relationships as templates for pun generation. In Proceedings of the Workshop on Computational Approaches to Linguistic Creativity, CALC ’09, pages 24–31, Stroudsburg, PA, USA, 2009. Association for Computational Linguistics.
- R. Hunicke, M. LeBlanc, and R. Zubek. Mda: A formal approach to game design and game research. 2004.
- D. Jurafsky and J. H. Martin. N-grams. 2014.
- B.-M. Justin McKay. Generation of idiom-based witticism to aid second language learning. Proceedings of April Fools’ Day Workshop on Computational Humour (TWLT 20), pages 77–87, April 2002.
- J. T. Kao, R. Levy, and N. D. Goodman. A computational model of linguistic humor in puns. Cognitive Science, 40(5):1270–1285, 2016.
- A. Karpathy, J. Johnson, and F. Li. Visualizing and understanding recurrent networks. CoRR, abs/1506.02078, 2015. 70
- C. Kiddon and Y. Brun. That’s what she said: Double entendre identification. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL), pages 89–94, Portland, OR, USA, June 2011. http://dl. acm.org/citation.cfm?id=2002756ACM ID: 2002756.
- C. Kim and K. Shim. Text: Automatic template extraction from heterogeneous web pages. IEEE Transactions on Knowledge and Data Engineering, 23(4):612– 626, April 2011.
- A. Koestler. The Act of Creation. An Arkana book : psychology/psychiatry. Arkana, 1964.
- A. Krikmann. Contemporary linguistic theories of humour. Folklore: Electronic Journal of Folklore, (33):27–58.
- G. Lessard and M. Levison. Computational modelling of linguistic humour, tom swifties. ALLClACIi92 Conference Abstracts, pages 175–178, 1992.
- V. I. Levenshtein. Binary codes capable of correcting deletions, insertions, and reversals. In Soviet physics doklady, volume 10, pages 707–710, 1966.
- B. Magnini and G. Cavaglià. Integrating subject field codes into wordnet. In Proceedings of the Second International Conference on Language Resources and Evaluation (LREC-2000), Athens, Greece, May 2000. European Language Resources Association (ELRA). ACL Anthology Identifier: L00-1167.
- J. C. Mallery. Thinking about foreign policy: Finding an appropriate role for artificially intelligent computers. In Master’s thesis, M.I.T. Political Science Department, 1988.
- R. Manurung, G. Ritchie, H. Pain, A. Waller, D. Mara, and R. Black. The construction of a pun generator for language skills development. Applied Artificial Intelligence, 22(9):841–869, 2008.
- R. Manurung, G. Ritchie, and H. Thompson. Using genetic algorithms to create meaningful poetic text. Journal of Experimental & Theoretical Artificial Intelligence, 24(1):43–64, 2012.
- R. Mihalcea and C. Strapparava. Making computers laugh: Investigations in automatic humor recognition. In HLT/EMNLP 2005, Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference, 6-8 October 2005, Vancouver, British Columbia, Canada, pages 531–538. The Association for Computational Linguistics, 2005.
- G. A. Miller. Wordnet: A lexical database for english. Commun. ACM, 38(11):39– 41, Nov. 1995. 71
- M. Minsky. Jokes and the Logic of the Cognitive Unconscious, pages 175–200. Springer Netherlands, Dordrecht, 1984.
- M. Mulder and A. Nijholt. Humour research: State of art. 02(34):–, 9 2002. Imported from CTIT.
- MyOxygen. Rise of the bots. http://www.myoxygen.co.uk/blog/ rise-of-the-bots/, 2016.
- S. Petrovic and D. Matthews. Unsupervised joke generation from big data. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 228–232, Sofia, Bulgaria, August 2013. Association for Computational Linguistics.
- G. Pilato, A. Augello, G. Vassallo, and S. Gaglio. Ehebby: An evocative humorist chat-bot. Mobile Information Systems, 4(3):165–181, 2008.
- V. Raskin. Semantic Mechanisms of Humor. Studies in Linguistics and Philosophy. D. Reidel, 1 edition, 1985.
- V. Raskin. A little metatheory: Thought on what a theory of computational humor should look like, 2012.
- V. Raskin and S. Attardo. Non-literalness and non-bona-fide in language: An approach to formal and computational treatments of humor. Marcelo Dascal, Pragmatics & Cognition 2:1, pages 31–69, 1994.
- G. Ritchie. Developing the incongruity-resolution theory. 1999.
- G. Ritchie. Current directions in computational humour. Artificial Intelligence Review, 16(2):119–135, 2001.
- G. Ritchie. The structure of forced reinterpretation jokes. Proceedings of April Fools’ Day Workshop on Computational Humour (TWLT 20), pages 47–56, April 2002.
- G. Ritchie. Computational mechanisms for pun generation. In Proceedings of the 10th European Natural Language Generation Workshop., pages 125–132, Department of Computer Science, University of Aberdeen, Aberdeen AB243UE, Scotland, 2005. ACL Anthology.
- B. Rose. Stand-up comedy using only siri, alexa, cortana and google home. https://www.youtube.com/watch?v=rO-89oBeBbQ.
- A. Schopenhauer. The World as Will and Representation. Number v. 1 in Dover books on philosophy. Dover Publications, 1958.
- D. Shahaf, E. Horvitz, and R. Mankoff. Inside jokes: Identifying humorous cartoon captions. In KDD, pages 1065–1074. ACM, 2015. 72
- D. Shahaf, E. Horvitz, and R. Mankoff. Inside jokes: Identifying humorous cartoon captions. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’15, pages 1065– 1074, New York, NY, USA, 2015. ACM.
- A. Sharan and M. L. Joshi. An algorithm for finding document concepts using semantic similarities from wordnet ontology. IJCVR, 1(2):147–157, 2010.
- H. Spencer. The Physiology of Laughter. Macmillan, 1860.
- O. Stock and C. Strapparava. Getting serious about the development of computational humor. In G. Gottlob and T. Walsh, editors, IJCAI-03, Proceedings of the Eighteenth International Joint Conference on Artificial Intelligence, Acapulco, Mexico, August 9-15, 2003, pages 59–64. Morgan Kaufmann, 2003.
- O. Stock and C. Strapparava. Hahacronym: Humorous agents for humorous acronyms. Humor-International Journal of Humor Research, 16(3):297–314, 2003.
- J. Taylor. Computational Recognition of Humor in a Focused Domain. University of Cincinnati, 2004.
- J. Taylor. Do jokes have to be funny: Analysis of 50 "theoretically jokes". In Artificial Intelligence of Humor, Papers from the 2012 AAAI Fall Symposium, Arlington, Virginia, USA, November 2-4, 2012, volume FS-12-02 of AAAI Technical Report. AAAI, 2012.
- Thricedotted. Found lexicons, generated grammars. https://www.youtube. com/watch?v=e7lxHlp2gGU.
- A. Valitutti. How many jokes are really funny? towards a new approach to the evaluation of computational humour generators. In Proceedings of International Workshop on Natural Language Processing and Cognitive Science (NLPCS 2011), 2011.
- A. Valitutti, H. Toivonen, A. Doucet, and J. M. Toivanen. "let everything turn well in your wife": Generation of adult humor using lexical constraints. In ACL (2), pages 243–248. The Association for Computer Linguistics, 2013.
- C. Venour. The computational generation of a class of puns. Master’s thesis, Queen’s University, Kingston, Ontario, 1999.
- A. Waller, R. Black, D. A. Mara, H. Pain, G. Ritchie, and R. Manurung. Evaluating the standup pun generating software with children with cerebral palsy. ACM Transactions on Accessible Computing (TACCESS), 1(3):1–27.
- G. V. D. Zwaag. Apple zoekt een grappenmaker voor siri: heb jij genoeg humor om te helpen? https://www.iculture.nl/nieuws/siri-vacature-grappen-bedenken/, 2016.








