Big Data in the cloud: je bedrijf in de wolken?
Data is niet meer weg te denken uit de hedendaagse maatschappij. Denk maar aan de vele mails die bedrijven hebben verzonden in verband met de invoering van de GDPR; hoeveel privacy-overeenkomsten heb je niet opnieuw moeten aanvaarden? Dit geeft een indicatie dat bedrijven data-analyses uitvoeren. Doet een bedrijf dit niet, dan mist het kostbare informatie over zijn klanten. Data is een belangrijke bron van informatie: The world's most valuable resource is no longer oil, but data volgens The Economist. Per minuut worden gigantische hoeveelheden data geproduceerd. Waar moetendeze data naartoe? Wie gaat deze data behandelen zodat enkel zinvolle informatie opgeslagen wordt? Maar het belangrijkste: hoe en waar gaan we de data verwerken? En dat vormt de focus van deze scriptie.
Traditionele systemen voldoen niet meer of zijn te duur om de gigantische hoeveelheden data te verwerken of op te slaan. Bedrijven moeten vaak elders op zoek naar een manier om hun data op te slaan en er vervolgens analyses mee uit te voeren. Momenteel bestaan er heel veel verschillende mogelijkheden om big data op te slaan en te verwerken, denk hierbij aan Hadoop, Spark, Flink, Samza, Dremel... Veel van die systemen zijn heel groot en vragen veel tijd voor installatie en configuratie. Enerzijds is het daardoor voor KMO’s niet opportuun om hiermee data-analyses uit te voeren, maar anderzijds missen ze wel kostbare informatie. Vanuit dat idee vertrok IntoData met de vraag om onderzoek te doen naar enkele oplossingen voor dit probleem. De oplossing van dit probleem bevindt zich in cloudplatformen.
Cloudplatformen
Een cloudplatform is zoals een programma op je eigen pc, alleen draait dit programma in de cloud. Wat is daar nu zo handig aan? Wel, het kost veel minder tijd en geld om servers op te starten en te configureren in de cloud dan zelf voor alles te zorgen. Bijvoorbeeld: een Apache Spark server opzetten in de Google Cloud duurt nog geen vijf minuten, je eigen server opzetten kost al snel een of twee dagen. Momenteel zien we drie grote spelers in de cloud: Google, Amazon en Azure (Microsoft). Elk van deze spelers biedt zijn eigen cloudplatformen aan voor heel veel verschillende toepassingen. IntoData heeft ervoor gekozen om Google BigQuery, Google Cloud Dataproc en Amazon EMR verder uit te diepen,aangezien deze drie systemen veelbelovend leken voor een (relatief) lage prijs. Dit werd gedaan aan de hand van een vergelijkende studie, waarbij elk van de tools werdafgetoetst aan enkele requirements en negen queries werden uitgevoerd op elk van de tools. Een query is een zoekopdracht in een databank die eventueel enkele gegevens teruggeeft.
Apache Spark
Google Cloud Dataproc en Amazon EMR zijn twee cloudplatformen gebaseerd op Apache Spark, een framework dat toelaat om gigantische hoeveelheden data te verwerken op meer dan één server. Elke server doet een stukje van de verwerking,waarna de resultaten van elke server samengebracht worden tot het gewenste resultaat. Dit is beter gekend als het MapReduce-principe. Het grote voordeel van MapReduce is dat de data niet mooi opgeruimd hoeft te zijn voor de verwerking start. De data mag onzuiverheden bevatten zoals niet ingevulde waarden of verkeerd opgemaakte waarden.
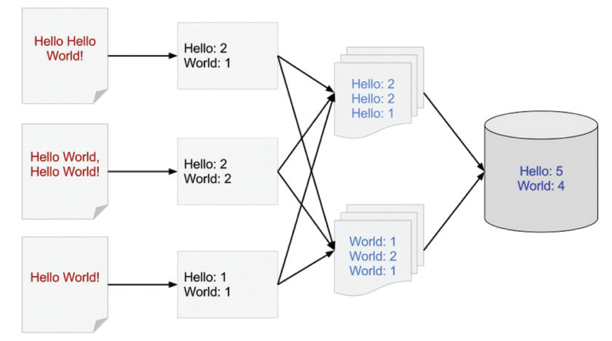
Figuur 1: MapReduce-principe (Sato, 2012)
Figuur 1 legt eenvoudig het principe van Apache Spark uit. Links zie je een aantal bestanden die de woorden ‘Hello’ en ‘World’ bevatten. In de eerste stap worden deze woorden gesplitst en wordt er geteld hoeveel keer een woord voorkomt. In de tweede stap worden deze aantallen samengevoegd tot één resultaat per woord. Dat resultaat wordt uiteindelijk in stap drie opgeslagen.
Dremel
Google BigQuery is gebaseerd op Dremel. Dremel is qua principe vergelijkbaar met Apache Spark, aangezien het ook toelaat om gigantische hoeveelheden data te verwerken over verschillende servers. Maar Dremel slaat de data op een andere manier op dan Apache Spark, waardoor er een grote snelheidswinst optreedt. Dit is het best tevergelijken met een simpele tabel: Dremel slaat data op per kolom,terwijl Apache Spark data opslaat per rij. Daardoor kan Dremel de data beter comprimeren (of verkleinen) omdat Dremel zeker weet welke soort data in een kolom zit,terwijl Apache Spark dit niet weet bij een volledige rij. Bijvoorbeeld: in een volledige rij kunnen cijfers en tekst door elkaar voorkomen,terwijl in een kolom enkel cijfers zitten. Een nadeel van Dremel is dat de data reeds mooi opgeruimd moet zijn alvorens ze opgeslagen kanworden.
Cijfers
Requirements
Elk van de tools werd aan een aantal requirements afgetoetst, hierbij werd een score gegeven van één tot vijf, gebaseerd op hoe goed elke tool scoort op het requirement. Google BigQuery scoort gemiddeld 4/5, Google Cloud Dataproc en Amazon EMR scoren gemiddeld 3/5. Uit statistische analyses van de scores bleek dat geen van de drie tools beter scoort:er waren geen significante verschillen aantoonbaar.
Uitvoeringstijden queries
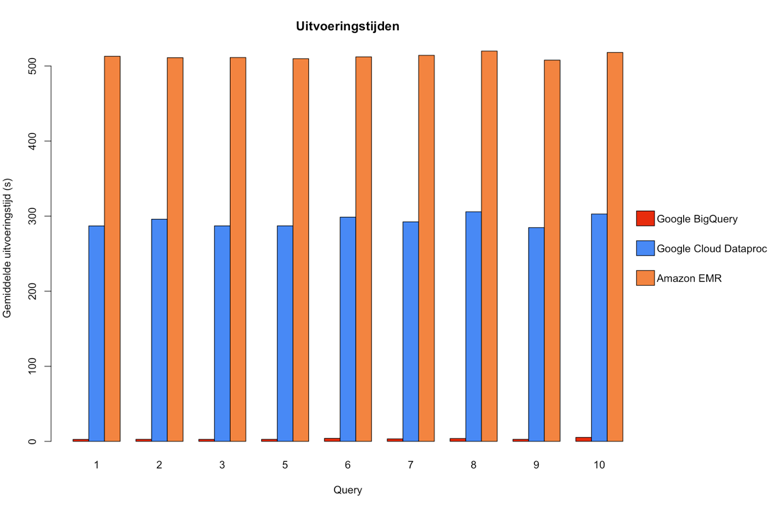
Figuur 2: Grafiek uitvoeringstijden
De negen queries in dit onderzoek werden een aantal keer uitgevoerd op een dataset van boetes uit de Verenigde Staten, goed voor zo’n 9GB aan data. Figuur 2 toont een overzicht van de gemiddelde uitvoeringstijd per query. Daaruit blijkt dat Google BigQuery de absolute winnaar is op het gebied van uitvoeringstijd. Een query duurt er gemiddeld drie seconden (zie pijl) in vergelijking met Google Cloud Dataproc, met gemiddeld vijf minuten en Amazon EMR,met gemiddeld acht minuten.
Conclusie
Zijn cloudplatformen nu een rendabele oplossing voor een KMO? Dit onderzoek wees uit dat elk van de drie tools zijn eigen use case heeft, maar ook dat ze zeker geschikt zijn voor KMO’s. Een analyse op een cloudplatform kost een paar honderd euro, wat in vergelijking met een eigen server relatief weinig is. Je kan de server op de cloudplatformen namelijk verwijderen wanneer je analyse afgerond is, terwijl je je eigen server niet zomaar kan verwijderen, waardoor die bijgevolg vaker staat te draaien voor niets.
Kortom: gigantische hoeveelheden data verwerken met weinig configuratiewerk en weinig kosten, waarom zou je niet in de cloud werken?
Bibliografie
Sato, K. (2012). An Inside Look at Google BigQuery. Google.
The Economist (2017, 6 mei). The world’s most valuable resource is no longer oil, but data. The Economist. Geraadpleegd via https://www.economist.com/leaders/2017/05/06/the-worlds-most-valuable-r… op 4 augustus 2018.
Bibliografie
Adam, H. (2017, maart 26). Back to Basics: What is Data Onboarding? Verkregen van https://www.lotame.com/back-basics-data-onboarding/
Amazon. (2017a). Amazon EMR Product Details. Verkregen van https://aws.amazon.com/emr/details/
Amazon. (2017b). Apache Spark om Amazon EMR. Verkregen van https://aws.amazon.com/emr/details/spark/
Amazon. (2017c, mei 2). Data warehousing in the era of Big Data: Deep Dive into Amazon Redshift. Verkregen van https://www.slideshare.net/AmazonWebServices/datawarehousing-in-the-era…
Amazon. (2018a). Amazon EMR Product Details. Verkregen van https://aws.amazon.com/emr/details/
Amazon. (2018b). Overview of Amazon EMR. Verkregen van https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-overview.html
Apache. (2017). Apache Nutch. Verkregen van http://nutch.apache.org/
Bappalige, S. P. (2014, augustus 26). An introduction to Apache Hadoop for big data. Verkregen van https://opensource.com/life/14/8/intro-apache-hadoop-big-data
Consortium, A. B. (2008). MoSCoW Prioritisation. Verkregen van https://www.agilebusiness.org/content/moscow-prioritisation-0
DataFlair. (2017, april 1). Lazy Evaluation in Apache Spark – A Quick guide. Verkregen van https://data-flair.training/blogs/apache-spark-lazy-evaluation/
Google. (2012). An Inside Look at Google BigQuery. Verkregen van https://cloud.google.com/files/BigQueryTechnicalWP.pdf
Google. (2017). Cloud Dataproc. Verkregen van https://cloud.google.com/dataproc/
Google. (2018a). Cloud Dataflow. Verkregen van https://cloud.google.com/dataflow/
Google. (2018b). Cloud Dataproc. Verkregen van https://cloud.google.com/dataproc/?hl=nl
Google. (2018c). Cloud Dataproc Pricing. Verkregen van https://cloud.google.com/dataproc/pricing
IBM. (2018). What is MapReduce? Verkregen van https://www.ibm.com/analytics/hadoop/mapreduce
Intellipaat. (g.d.). Loading and Saving your Data. Verkregen van https://intellipaat.com/tutorial/spark-tutorial/loading-and-saving-your…
Jang, C. (2016, maart 31). Google Cloud Platform: Data & Analytics. Verkregen van https://www.slideshare.net/cjang99/google-cloud-platform-rockplace-big-…
Kshirsagar, M. M. (2016, september 17). Cortana Intelligence Suite Services Workshop. Verkregen van https://blogs.msdn.microsoft.com/maheshkshirsagar/2016/09/17/cortanaint…
Langit, L. (2013, mei 18). Hadoop MapReduce Fundamentals. Verkregen van https://www.slideshare.net/lynnlangit/hadoop-mapreduce-fundamentals-214…
Lardinois, F. (2013, september 18). Google’s BigQuery Introduces Streaming Inserts And Time-Based Queries For Real-Time Analytics. Verkregen van https://techcrunch.com/2013/09/18/googles-bigquery-introduces-streaming…
Laskowski, J. (g.d.). RDD — Resilient Distributed Dataset. Verkregen van https://jaceklaskowski.gitbooks.io/mastering-apache-spark/content/spark…
Laufer, A. (2018, februari 5). Autoscaling Google Dataproc Clusters. Verkregen van https://blog.doit-intl.com/autoscaling-google-dataproc-clusters-21f34be…
Melnik, S., Gubarev, A., Long, J. J., Romer, G., Shivakumar, S., Tolton, M. & Vassilakis, T. (2010). Dremel: Interactive Analysis of Web-Scale Datasets. In Proc. of the 36th Int’l Conf on Very Large Data Bases (pp. 330–339). Verkregen van http://www.vldb2010.org/accept.htm
Nucleus. (2017, januari 16).Wat is het verschil tussen IaaS, PaaS, SaaS en UaaS. Verkregen van https://www.nucleus.be/blog/uptime-as-a-service/verschil-iaas-paas-saas…
Rouse, M. (2013). Apache HBase. Verkregen van http://searchdatamanagement.techtarget.com/definition/Apache-HBase
Rouse, M. (2017). Amazon Elastic MapReduce (Amazon EMR). Verkregen van http://searchaws.techtarget.com/definition/Amazon- Elastic- MapReduce-Amazon-EMR
Sato, K. (2012). An Inside Look at Google BigQuery. Google.
Shailna, P. (2017, april 26). Data Block in HDFS | HDFS Blocks & Data Block Size. Verkregen van https://data-flair.training/blogs/data-block/
Tereshko, T. (2017, januari 5). Why Dataproc — Google’s managed Hadoop and Spark offering is a game changer. Verkregen van https://hackernoon.com/why-dataprocgoogles-managed-hadoop-and-spark-off…
Zaharia, M., Chowdhury, M., Das, T., Dave, A., Ma, J., McCauley, M., . . . Scott Shenker, I. S. (2012, april 25). Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. University of California, Berkeley.
Zaharia, M., Xin, R. S., Wendell, P., Das, T., Armbrust, M., Dave, A., . . . Stoica, I. (2016). Apache Spark: A Unified Engine For Big Data Processing. Communications of the ACM, 59(11). Verkregen van https://cacm.acm.org/magazines/2016/11/209116-apache-spark/abstract








