Een kijkje in het brein van Artificiële Intelligentie
In maart 2016 versloeg Google’s computerprogramma AlphaGo de wereldkampioen Lee Sedol in het bordpsel Go. De wereld van artificiële intelligentie daverde op zijn grondvesten. Go is namelijk een van de moeilijkste bekende bordspelen, vele honderden keren moeilijker voor een computer dan bijvoorbeeld schaken. Bijna niemand had verwacht dat deze mijlpaal bereikt zou worden voor 2020.
Hoe is Google er dan in geslaagd om de wereldkampioen te verslaan? Het antwoord ligt bij dezelfde systemen die meer en meer ons dagelijks leven rechtstreeks en onrechtstreeks beïnvloeden: neurale netwerken. Een neuraal netwerk is een model dat ruwweg gebaseerd is op hoe menselijke hersens werken: een groep hersencellen (neuronen) werkt samen door signalen naar elkaar door te sturen om zo een uitvoersignaal te genereren.
Wat neurale netwerken speciaal maakt is het feit dat ze kunnen leren uit hun fouten. Zo werd AlphaGo getraind door duizenden wedstrijden tegen zichzelf te spelen, en zo te leren welke strategie het meest succesvol was. Eén van de wetenschappers achter AlphaGo, Thore Graepel, vat het als volgt samen:
“Hoewel we de machine geprogrammeerd hebben om te spelen, hebben we geen idee wat ze gaat doen. […] Wij maken enkel de datasets en het trainingsalgoritme. Maar de zetten die ze dan maakt zijn buiten onze controle – en veel beter dan wat wij, als Go spelers, zouden kunnen verzinnen.”
Deze uitspraak duidt zowel de meest intrigerende eigenschap als één van de grootste problemen aan van neurale netwerken: ze zijn black boxes. Dit betekent dat niemand, zelfs niet de ontwerper van het neuraal netwerk, kan zien of begrijpen hoe het netwerk “denkt”: wij geven het gewoon een vraag, en het netwerk geeft een antwoord terug.
Deze eigenschap lijkt op het eerste zicht misschien indrukwekkend, maar als we er wat langer over nadenken merken we dat het ook een zeer gevaarlijke eigenschap is. Stel bijvoorbeeld dat we een neuraal netwerk willen trainen om een auto te besturen, om zo een zelfrijdende auto te ontwikkelen. Hoe weten we ooit dat het netwerk altijd de juiste beslissing zal maken, en niet volledig zal crashen als er bijvoorbeeld een slecht verlichte fietser passeert?
Gelukkig bestaan er naast neurale netwerken nog andere modellen die uit ervaring kunnen leren. Bij veel van deze technieken kunnen we wel inzicht krijgen in wat ze geleerd hebben. Zo bestaan er bijvoorbeeld technieken die een aantal als-dan regels aanleren, bv. “Als de auto voor ons dichtbij komt, dan moeten we remmen”. Zulke modellen kunnen we gemakkelijk interpreteren door gewoon de als-dan regels af te lezen.
Het probleem hier is dat zulke interpreteerbare modellen op grote problemen veel minder goed presteren dan neurale netwerken. Technieken gebaseerd op als-dan regels zouden bijvoorbeeld nooit in staat zijn geweest om de wereldkampioen Go te verslaan. We moeten dus een keuze maken: sterke prestaties, of een interpreteerbaar model.
In deze thesis introduceren we een nieuwe techniek om deze keuze te verzachten. We doen dit door middel van distillatie. Dit betekent dat we een neuraal netwerk eerst een taak aanleren, om vervolgens de kennis van het neuraal netwerk over te brengen naar een meer interpreteerbaar model.
We kunnen het neuraal netwerk hier beschouwen als een leerkracht, en het interpreteerbaar model als een leerling. De leerling kan uit zichzelf een probleem moeilijk oplossen, maar met de hulp van een leerkracht lukt het wel. Deze aanpak laat ons toe om interpreteerbare modellen problemen te laten oplossen die ze op zichzelf niet zouden aankunnen. Zo combineren we het beste van beide werelden: sterke prestaties en een interpreteerbaar model.
We probeerden onze techniek uit op een klassiek testprobleem: het balanceren van een paal. In dit probleem vertrekken we van een simulatie van een paal die rechtop staat en onderaan op één punt vastgemaakt is. Het doel is om de paal te balanceren door ze naar links of naar rechts te bewegen. Dit is een voorbeeld van een probleem dat een neuraal netwerk gemakkelijk kan oplossen, maar een model gebaseerd op als-dan regels niet.
Het experiment loopt als volgt: eerst trainen we een neuraal netwerk met 128 neuronen om de paal te balanceren. Vervolgens testen we ook of een model met 30 als-dan regels in staat is om het probleem op te lossen. Ten slotte distilleren we de kennis van het neuraal netwerk in een nieuw als-dan model. Deze als-dan regels hebben hier bijvoorbeeld de vorm: “Als de paal overwegend naar links helt, en aan het vallen is, duw dan de paal naar rechts.”
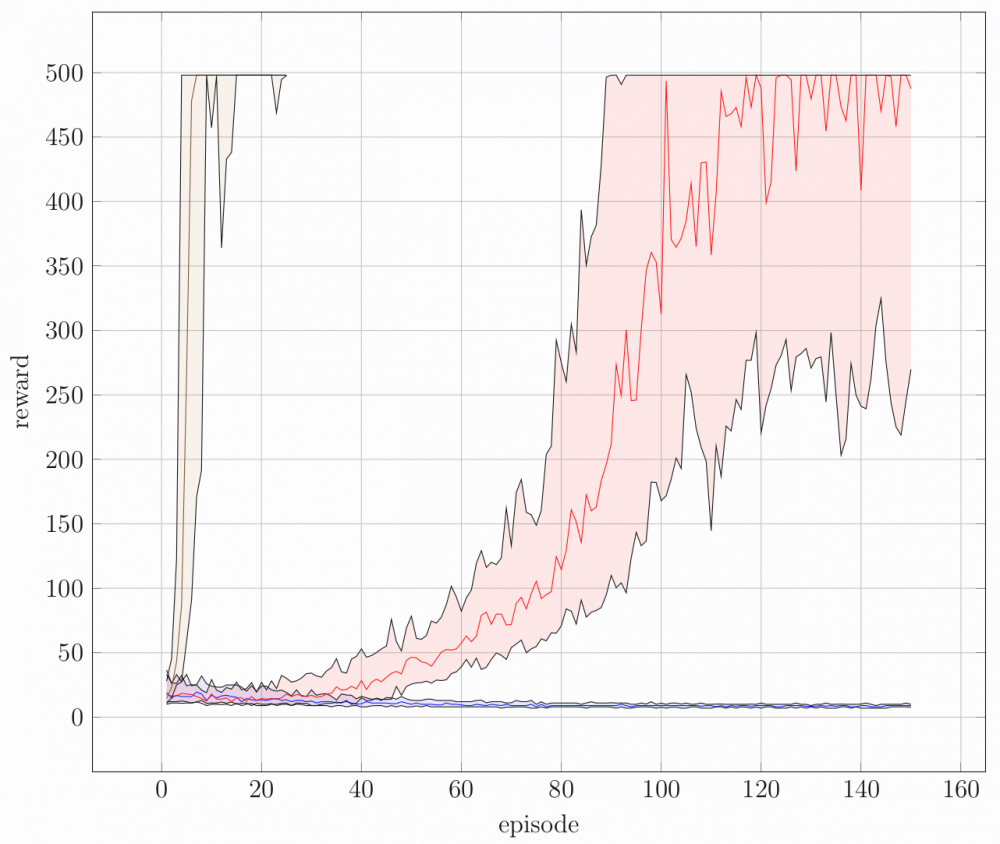
De resultaten van het experiment worden weergegeven in de figuur. "Episode" betekent de "poging", iedere keer dat de paal naar beneden valt begint een nieuwe episode. De modellen kregen elk 150 pogingen. "Reward" is de prestatie van het model, hoe langer de paal omhoog blijft, hoe hoger de reward. Iedere curve geeft dus weer hoe goed een model presteert in functie van de tijd. De rode, blauwe en bruine curve komen respectievelijk overeen met het neuraal netwerk, het model met 30 als-dan regels, en het gedistilleerde model met 5 als-dan regels. We zien dat de blauwe curve beneden blijft, wat weergeeft dat het model met 30 als-dan regels niet in staat is om het probleem op te lossen. In tegenstelling tot de blauwe curve, zien we de bruine curve wel zeer snel stijgen. Dit betekent dat een model met slechts 5 als-dan regels via distillatie het probleem vrijwel meteen kan oplossen.
Hoewel de techniek hier slechts werd toegepast op een speelgoedvoorbeeld, zijn de resultaten al zeer veelbelovend. Er bestaat tot nu toe namelijk nog geen techniek die een neuraal netwerk op dit klassiek probleem op zo’n compacte manier kan samenvatten. De volgende stap is nu om hetzelfde idee te verfijnen en uit te breiden. We kunnen het dan toepassen op zwaardere en zwaardere problemen, totdat we uiteindelijk misschien toch een kijkje kunnen nemen in het bovenmenselijke brein van AlphaGo.
Bibliografie
[1] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the Knowledge in a Neural
Network. arXiv:1503.02531 [cs, stat], March 2015.
[2] Andrei A. Rusu, Sergio Gomez Colmenarejo, Caglar Gulcehre, Guillaume Desjardins,
James Kirkpatrick, Razvan Pascanu, Volodymyr Mnih, Koray Kavukcuoglu, and Raia
Hadsell. Policy Distillation. arXiv:1511.06295 [cs], November 2015.
[3] L. A. Zadeh. Fuzzy logic and approximate reasoning. Synthese, 30(3):407–428, September 1975.
[4] F. Rosenblatt. The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65(6):386–408, 1958.
[5] Yann LeCun and Corinna Cortes. MNIST handwritten digit database. 2010.
[6] Alex Krizhevsky. Learning Multiple Layers of Features from Tiny Images. page 60.
[7] Alex Graves, Abdel-rahman Mohamed, and Geoffrey Hinton. Speech Recognition with Deep Recurrent Neural Networks. arXiv:1303.5778 [cs], March 2013.
[8] Caroline Chan, Shiry Ginosar, Tinghui Zhou, and Alexei A. Efros. Everybody Dance Now. arXiv:1808.07371 [cs], August 2018.
[9] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going Deeper with Convolutions. arXiv:1409.4842 [cs], September 2014.
[10] Yanghao Li, Yuntao Chen, Naiyan Wang, and Zhaoxiang Zhang. Scale-Aware Trident Networks for Object Detection. arXiv preprint arXiv:1901.01892, 2019.
[11] Seonghyeon Nam, Yunji Kim, and Seon Joo Kim. Text-Adaptive Generative Adversarial Networks: Manipulating Images with Natural Language. arXiv:1810.11919 [cs], October 2018.
[12] Shauharda Khadka and Kagan Tumer. Evolution-Guided Policy Gradient in Reinforcement Learning. arXiv:1805.07917 [cs, stat], May 2018.
[13] Paul Voigt and Axel von dem Bussche. The EU General Data Protection Regulation (GDPR): A Practical Guide. Springer Publishing Company, Incorporated, 1st edition, 2017.
[14] Philippe Leray and Patrick Gallinari. Feature Selection with Neural Networks. Behaviormetrika, 26(1):145–166, 1999.
[15] Yann LeCun, John S Denker, and Sara A Solla. Optimal brain damage. In Advances in Neural Information Processing Systems, pages 598–605, 1990.
[16] Babak Hassibi, David G Stork, and Gregory J Wolff. Optimal brain surgeon and general network pruning. In IEEE International Conference on Neural Networks, pages 293–299. IEEE, 1993.
[17] Mark Craven and Jude W Shavlik. Extracting tree-structured representations of trained networks. In Advances in Neural Information Processing Systems, pages 24–30, 1996.
[18] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing Atari with Deep Reinforcement Learning. arXiv:1312.5602 [cs], December 2013.
[19] Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. SVCCA:
Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability.
[20] Bin Liu, Ruiming Tang, Yingzhi Chen, Jinkai Yu, Huifeng Guo, and Yuzhou Zhang. Feature Generation by Convolutional Neural Network for Click-Through Rate Prediction. The World Wide Web Conference on - WWW ’19, pages 1119–1129, 2019.
[21] Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. Deep Interest Network for Click-Through Rate Prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’18, pages 1059–1068, New York, NY, USA, 2018. ACM.
[22] Shai Shalev-Shwartz, Shaked Shammah, and Amnon Shashua. Safe, Multi-Agent, Reinforcement Learning for Autonomous Driving. arXiv:1610.03295 [cs, stat], October 2016.
[23] M. Kuderer, S. Gulati, and W. Burgard. Learning driving styles for autonomous vehicles from demonstration. In 2015 IEEE International Conference on Robotics and Automation (ICRA), pages 2641–2646, May 2015.
[24] Craig Saunders, Alexander Gammerman, and Volodya Vovk. Ridge regression learning algorithm in dual variables. 1998.
[25] David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge. Nature, 550(7676):354, 2017.
[26] S. P. K. Spielberg, R. B. Gopaluni, and P. D. Loewen. Deep reinforcement learning approaches for process control. In 2017 6th International Symposium on Advanced Control of Industrial Processes (AdCONIP), pages 201–206, May 2017.
[27] Roger J Lewis. An introduction to classification and regression tree (CART) analysis. In Annual Meeting of the Society for Academic Emergency Medicine in San Francisco, California, volume 14, 2000.
[28] Andy Liaw, Matthew Wiener, et al. Classification and regression by randomForest. R news, 2(3):18–22, 2002.
[29] R Bracewell. Heaviside’s Unit Step Function. The Fourier Transform and Its Applications, pages 61–65, 2000.
[30] I Stephen. Perceptron-based learning algorithms. IEEE Transactions on neural networks, 50(2):179, 1990.
[31] Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org.
[32] Maithra Raghu, Ben Poole, Jon Kleinberg, Surya Ganguli, and Jascha Sohl-Dickstein. On the Expressive Power of Deep Neural Networks. arXiv:1606.05336 [cs, stat], June 2016.
[33] Guido F Montufar, Razvan Pascanu, Kyunghyun Cho, and Yoshua Bengio. On the Number of Linear Regions of Deep Neural Networks.
[34] Moshe Sniedovich. Dynamic Programming: Foundations and Principles. CRC press, 2010.
[35] Alexander Schrijver. Theory of Linear and Integer Programming. John Wiley & Sons, 1998.
[36] Lawrence Davis. Handbook of genetic algorithms. 1991.
[37] Emile Aarts and Jan Korst. Simulated annealing and Boltzmann machines. 1988.
[38] Matthew D Zeiler. ADADELTA: An adaptive learning rate method. arXiv preprint arXiv:1212.5701, 2012.
[39] Douglas M Hawkins. The problem of overfitting. Journal of chemical information and computer sciences, 44(1):1–12, 2004.
[40] Ron Kohavi et al. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Ijcai, volume 14, pages 1137–1145. Montreal, Canada, 1995.
[41] Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. Adaptive Computation and Machine Learning. MIT Press, Cambridge, Mass, 1998.
[42] Christopher John Cornish Hellaby Watkins. Learning from delayed rewards. 1989.
[43] Gerald Tesauro. Temporal difference learning and TD-Gammon. Communications of the ACM, 38(3):58–68, 1995.
[44] Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. arXiv:1509.02971 [cs, stat], September 2015.
[45] David R. Hardoon, Sandor Szedmak, and John Shawe-Taylor. Canonical Correlation Analysis: An Overview with Application to Learning Methods. Neural Computation, 16(12):2639–2664, December 2004.
[46] Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. OpenAI Gym. 2016.
[47] Antonio Polino, Razvan Pascanu, and Dan Alistarh. Model compression via distillation and quantization. arXiv:1802.05668 [cs], February 2018.
[48] Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv:1704.04861 [cs], April 2017.
[49] Aaron van den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, George van den Driessche, Edward Lockhart, Luis C. Cobo, Florian Stimberg, Norman Casagrande, Dominik Grewe, Seb Noury, Sander Dieleman, Erich Elsen, Nal Kalchbrenner, Heiga Zen, Alex Graves, Helen King, Tom Walters, Dan Belov, and Demis Hassabis. Parallel WaveNet: Fast High-Fidelity Speech Synthesis. arXiv:1711.10433 [cs], November 2017.
[50] Ying Zhang, Tao Xiang, Timothy M. Hospedales, and Huchuan Lu. Deep Mutual Learning. arXiv:1706.00384 [cs], June 2017.
[51] Nicholas Frosst and Geoffrey Hinton. Distilling a Neural Network Into a Soft Decision Tree. arXiv:1711.09784 [cs, stat], November 2017.
[52] Xuan Liu, Xiaoguang Wang, and Stan Matwin. Improving the Interpretability of Deep Neural Networks with Knowledge Distillation. arXiv:1812.10924 [cs, stat], December 2018.
[53] Wojciech Marian Czarnecki, Siddhant M. Jayakumar, Max Jaderberg, Leonard Hasenclever, Yee Whye Teh, Simon Osindero, Nicolas Heess, and Razvan Pascanu. Mix&Match - Agent Curricula for Reinforcement Learning. arXiv:1806.01780 [cs, stat], June 2018.
[54] Stephane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning. arXiv:1011.0686 [cs, stat], November 2010.
[55] Himani Arora, Rajath Kumar, Jason Krone, and Chong Li. Multi-task Learning for Continuous Control. arXiv:1802.01034 [cs, stat], February 2018.
[56] Simon Schmitt, Jonathan J. Hudson, Augustin Zidek, Simon Osindero, Carl Doersch, Wojciech M. Czarnecki, Joel Z. Leibo, Heinrich Kuttler, Andrew Zisserman, Karen Simonyan, and S. M. Ali Eslami. Kickstarting Deep Reinforcement Learning. arXiv:1803.03835 [cs], March 2018.
[57] Wojciech Marian Czarnecki, Razvan Pascanu, Simon Osindero, Siddhant M. Jayak-umar, Grzegorz Swirszcz, and Max Jaderberg. Distilling Policy Distillation. arXiv:1902.02186 [cs, stat], February 2019.
[58] L. A. Zadeh. Fuzzy sets. Information and Control, 8(3):338–353, June 1965.
[59] Chris Cornelis. Wiskundige Modellering van Artificiële Intelligentie, 2018.
[60] Aldo De Luca and Settimo Termini. A definition of a nonprobabilistic entropy in the setting of fuzzy sets theory. Information and control, 20(4):301–312, 1972.
[61] E. H. Mamdani and S. Assilian. An experiment in linguistic synthesis with a fuzzy logic controller. International Journal of Man-Machine Studies, 7(1):1–13, January 1975.
[62] Tomohiro Takagi and Michio Sugeno. Fuzzy identification of systems and its applications to modeling and control. In Readings in Fuzzy Sets for Intelligent Systems, pages 387–403. Elsevier, 1993.
[63] J.-S.R. Jang. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Transactions on Systems, Man, and Cybernetics, 23(3):665–685, May-June/1993.
[64] Hirofumi Miyajima, Noritaka Shigei, and Hiromi Miyajima. Approximation Capabilities of Interpretable Fuzzy Inference Systems. page 8, 2015.
[65] Rui Pedro Paiva and António Dourado. Interpretability and learning in neuro-fuzzy systems. 2004.
[66] Stephen L Chiu. Fuzzy model identification based on cluster estimation. Journal of Intelligent & fuzzy systems, 2(3):267–278, 1994.
[67] M. Setnes, R. Babuska, U. Kaymak, and H. R. van Nauta Lemke. Similarity measures in fuzzy rule base simplification. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 28(3):376–386, June 1998.
[68] Saul Stahl. The evolution of the normal distribution. Mathematics magazine, 79(2):96–113, 2006.
[69] S. Guillaume. Designing fuzzy inference systems from data: An interpretability-oriented review. IEEE Transactions on Fuzzy Systems, 9(3):426–443, June 2001.
[70] Daniel Hein, Steffen Udluft, and Thomas A. Runkler. Generating Interpretable Fuzzy Controllers using Particle Swarm Optimization and Genetic Programming. Proceedings of the Genetic and Evolutionary Computation Conference Companion on - GECCO ’18, pages 1268–1275, 2018.








