Een Veelgebruikte Taak om de Balans Tussen Doelgericht en Gewoontegedrag te Meten Blijkt Niet Zo Optimaal te Zijn
Een veelgebruikte taak om beter te verstaan hoe mensen gebruik maken van doelgericht en gewoontegedrag werd recentelijk gesuggereerd niet optimaal te zijn om de balans tussen doelgericht en gewoontegedrag te meten. Wij wilden testen of dit het geval is en of we het gedrag in de taak beter kunnen begrijpen op een andere dimensie van gedrag. Het huidige onderzoek toont aan dat dit werkelijk het geval is en kaart aan dat toekomstig onderzoek een aantal factoren in rekening moet houden wanneer ze deze taak willen gebruiken.
Het is algemeen aanvaard dat organismen kunnen leren acties te kiezen door beloningen of straffen van hun acties te ervaren (instrumenteel leren; Skinner, 1938). Organismen kunnen echter ook leren over hun omgeving zonder directe beloning of straf te ervaren, en deze informatie kan ook worden gebruikt om toekomstige beslissingen te nemen (Tolman, 1948). Hoewel veel organismen in staat zijn om de uitkomsten van hun acties zorgvuldig te overwegen door gebruik te maken van de informatie over hun omgeving, herhalen ze vaak gewoon de acties die eerder tot een beloning leidden. Dit wordt vaak aangeduid als een onderscheid tussen doelgericht en gewoontegedrag.
Bij reinforcement learning (een machine learning-trainingsmethode gebaseerd op het belonen/straffen van gedrag) worden doelgericht en gewoontegedrag respectievelijk modelgebaseerde en modelvrije systemen genoemd. In hoeverre mensen net gebruik maken van modelgebaseerde of modelvrije systemen kan gemeten worden door hen een veelgebruikte besluitvormingstaak, de tweestapstaak genoemd, te laten uitvoeren (zie Figuur 1). In deze taak moeten mensen kiezen tussen verschillende figuurtjes op een scherm waarvan ze beloningen krijgen en reinforcement learning maakt het hier dan mogelijk een parameter vast te leggen die de balans voorsteld tussen de twee systemen. Voormalig onderzoek ging er in het algemeen van uit dat mensen een combinatie gebruiken van deze systemen (Daw, Gershman, Seymour, Dayan, & Dolan, 2011).
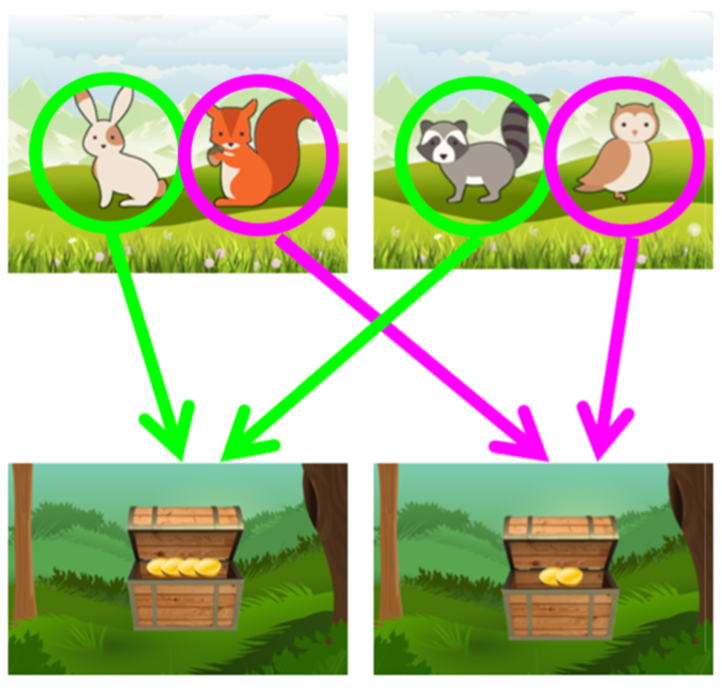
Figuur 1. Voorbeeld van de tweestapstaak. De figuurtjes die aangeduid zijn met groen leiden tot 4 muntjes, terwijl de figuurtjes aangeduid met roze leiden tot 2 muntjes.
Een recent onderzoek toonde echter aan dat duidelijke instructies over de taak ervoor zorgen dat deelnemers voornamelijk modelgebaseerde systemen gebruiken (da Silva & Hare, 2020). Bovendien wordt bepaald gedrag in de tweestapstaak niet bepaald door de dichotomie tussen modelgebaseerde en modelvrije systemen (Collins & Cockburn, 2020), maar kan als zodanig verkeerd worden geclassificeerd, wat ons begrip beperkt van wat er werkelijk gebeurt tijdens deze taak. Vandaar kunnen bepaalde gedragingen mogelijks beter begrepen worden op een andere dimensie van leren en besluitvorming door eventueel andere parameters te gebruiken in reinforcement learning. In de huidige studie hebben we onderzocht of de deelnemers ook voornamelijk modelgebaseerde systemen gebruiken met verbeterde instructies. Daarnaast hebben we ook bestudeert hoe de afweging tussen exploratie en exploitatie onze beslissingen aanstuurt door naar een andere parameter te kijken. Exploitatie verwijst naar iemand die een keuze selecteert die hij/zij als de meest optimale keuze beschouwt, terwijl exploratie verwijst naar het selecteren van een andere keuze omdat die persoon misschien wil weten of de andere optie beter is of niet.
De resultaten toonden aan dat de proefpersonen voornamelijk modelgebaseerde systemen gebruikten en meer exploreerden wanneer de figuurtjes op het scherm veranderden. Deze resultaten suggereren dat mensen voornamelijk modelgebaseerde strategieën gebruiken bij het uitvoeren van de tweestapstaak, wat waarschijnlijk afhangt van hoe goed de deelnemers de taakstructuur begrijpen. Aan de andere kant suggereren onze resultaten dat de afweging tussen exploratie en exploitatie een belangrijke rol speelt in hoe mensen zich gedragen in de tweestapstaak, en het sommige gedragstendensen meer zou kunnen verklaren dan wat we kunnen verklaren door simpelweg te kijken naar modelgebaseerde en modelvrije systemen. Een beter begrip van het gedrag in de tweestapstaak, naast het onderscheid tussen modelgebaseerd en modelvrij systemen, zou door toekomstig onderzoek moeten worden aangepakt. Verder moet toekomstig onderzoek zorgvuldig rekening houden met verschillende factoren bij het gebruik van de tweestapstaak, zoals hoe expliciet de taakinstructies zijn, hoe gemakkelijk de taak is en of de taakstructuur misclassificatie van modelgebaseerd en modelvrij leren voorkomt.
Referenties
Collins, A. G., & Cockburn, J. (2020). Beyond dichotomies in reinforcement learning. Nature Reviews Neuroscience, 21(10), 576-586. https://doi.org/10.1038/s41583-020-0355-6
da Silva, C. F., & Hare, T. A. (2020). Humans primarily use model-based inference in the two-stage task. Nature Human Behaviour, 4(10), 1053-1066. https://doi.org/10.1038/s41562-020-0905-y
Daw, N. D., Gershman, S. J., Seymour, B., Dayan, P., & Dolan, R. J. (2011). Model-based influences on humans’ choices and striatal prediction errors. Neuron, 69(6), 1204–1215.https://doi.org/10.1016/j.neuron.2011.02.027
Skinner, B. F. (1938). The behavior of organisms: An experimental analysis. In R.M. Elliot (Ed.), The Century Psychology Series (pp. 1–451). New York: Appleton-Century. https://www.scribd.com/document/283214535/Skinner-B-F-1938-the-Behavior-of-Organisms-An-Experimental-Analysis
Tolman, E.C. (1948). Cognitive maps in rats and men. Psychological Review, 55(4), 189–208. https://doi.org/10.1037/h0061626
Bibliografie
Akam, T., Costa, R., & Dayan, P. (2015). Simple Plans or Sophisticated Habits? State, Transition and Learning Interactions in the Two-Step Task. PLoS Computational Biology, 11(12), e1004648.https://doi.org/10.1371/journal.pcbi.1004648
Cogliati Dezza, I., Cleeremans, A., & Alexander, W. (2019). Should we control? The interplay between cognitive control and information integration in the resolution of the exploration-exploitation dilemma. Journal of Experimental Psychology: General, 148(6), 977–993. https://doi.org/10.1037/xge0000546
Cohen, J. D., McClure, S. M., & Yu, A. J. (2007). Should I stay or should I go? How the human brain manages the trade-off between exploitation and exploration. Philosophical transactions of the Royal Society of London. Series B, Biological sciences, 362(1481), 933–942. https://doi.org/10.1098/rstb.2007.2098
Collins, A. G., & Cockburn, J. (2020). Beyond dichotomies in reinforcement learning. Nature Reviews Neuroscience, 21(10), 576-586. https://doi.org/10.1038/s41583-020-0355-6
da Silva, C. F., & Hare, T. A. (2020). Humans primarily use model-based inference in the two-stage task. Nature Human Behaviour, 4(10), 1053-1066. https://doi.org/10.1038/s41562-020-0905-y
Daw, N. D., Gershman, S. J., Seymour, B., Dayan, P., & Dolan, R. J. (2011). Model-based influences on humans’ choices and striatal prediction errors. Neuron, 69(6), 1204–1215.https://doi.org/10.1016/j.neuron.2011.02.027
Daw, N. D., Niv, Y., & Dayan, P. (2005). Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control. Nature Neuroscience, 8(12), 1704–1711. https://doi.org/10.1038/nn1560
Daw, N. D. (2018). Are we of two minds? Nature neuroscience, 21(11), 1497-1499. https://doi.org/10.1038/s41593-018-0258-2
Dayan, P., & Niv, Y. (2008). Reinforcement learning: The Good, The Bad and The Ugly. Current Opinion in Neurobiology, 18(2), 185–196. https://doi.org/10.1016/j.conb.2008.08.003
Doll, B. B., Duncan, K. D., Simon, D. A., Shohamy, D., & Daw, N. D. (2015). Model-based choices involve prospective neural activity. Nature Neuroscience, 18(5), 767–772. https://doi.org/10.1038/nn.3981
Gershman, S. J., & Niv, Y. (2010). Learning latent structure: carving nature at its joints. Current opinion in neurobiology, 20(2), 251–256. https://doi.org/10.1016/j.conb.2010.02.008
Gershman, S. J. (2016). Empirical priors for reinforcement learning models. Journal of Mathematical Psychology, 71, 1–6. https://doi.org/10.1016/j.jmp.2016.01.006
Heitz, R. P. (2014). The speed-accuracy tradeoff: history, physiology, methodology, and behavior. Frontiers in Neuroscience, 8, 150. https://doi.org/10.3389/fnins.2014.00150
Ito, K. L., Cao, L., Reinberg, R., Keller, B., Monterosso, J., Schweighofer, N., & Liew, S. L. (2021). Validating Habitual and Goal-Directed Decision-Making Performance Online in Healthy Older Adults. Frontiers in aging neuroscience, 13, 702810. https://doi.org/10.3389/fnagi.2021.702810
Keramati, M., Dezfouli, A., & Piray, P. (2011). Speed/accuracy trade-off between the habitual and the goal-directed processes. PLoS Computational Biology, 7(5). https://doi.org/10.1371/journal.pcbi.1002055
Kool, W., Cushman, F. A., & Gershman, S. J. (2016). When Does Model-Based Control Pay Off? PLoS Computational Biology, 12(8), 1–34. https://doi.org/10.1371/journal.pcbi.1005090
Kool, W., McGuire, J. T., Rosen, Z. B., & Botvinick, M. M. (2010). Decision making and the avoidance of cognitive demand. Journal of Experimental Psychology: General, 139(4), 665–682. https://doi.org/10.1037/a0020198
Lee, S. W., Shimojo, S., & O’Doherty, J. P. (2014). Neural Computations Underlying Arbitration between Model-Based and Model-free Learning. Neuron, 81(3), 687–699. https://doi.org/10.1016/j.neuron.2013.11.028
Otto, A. R., Gershman, S. J., Markman, A. B., & Daw, N. D. (2013). The curse of planning: dissecting multiple reinforcement-learning systems by taxing the central executive. Psychological Science, 24(5), 751–761.https://doi.org/10.1177/0956797612463080
Otto, A. R., Raio, C. M., Chiang, A., Phelps, E. A., & Daw, N. D. (2013). Working-memory capacity protects model-based learning from stress. Proceedings of the National Academy of Sciences of the United States of America, 110(52), 20941–20946. https://doi.org/10.1073/pnas.1312011110
Piray, P., Toni, I., & Cools, R. (2016). Human Choice Strategy Varies with Anatomical Projections from Ventromedial Prefrontal Cortex to Medial Striatum. Journal of Neuroscience, 36(10), 2857–2867.https://doi.org/10.1523/JNEUROSCI.2033-15.2016
Radenbach, C., Reiter, A. M., Engert, V., Sjoerds, Z., Villringer, A., Heinze, H. J., Deserno, L., & Schlagenhauf, F. (2015). The interaction of acute and chronic stress impairs model-based behavioral control.Psychoneuroendocrinology, 53, 268–280. https://doi.org/10.1016/j.psyneuen.2014.12.017
Rescorla, R. A., & Wagner, A. (1972). A theory of Pavlovian conditioning: Variations in the effectiveness of reinforcement and nonreinforcement. In A.H. Black & W.F. Prokasy (Eds.), Classical Conditioning II: Current Research and Theory (pp. 64–99). New York: Appleton-Century-Crofts.https://pdfs.semanticscholar.org/afaf/65883ff75cc19926f61f181a6879277 89ad1.pdf
Rogers, R. D., & Monsell, S. (1995). Costs of a predictable switch between simple cognitive tasks. Journal of Experimental Psychology: General, 124(2), 207–231. https://doi.org/10.1037/0096-3445.124.2.207
Shapiro, S. S., & Wilk, M. B. (1965). An Analysis of Variance Test for Normality (Complete Samples). Biometrika, 52, 591-611. https://doi.org/10.1093/biomet/52.3-4.591
Skinner, B. F. (1938). The behavior of organisms: An experimental analysis. In R.M. Elliot (Ed.), The Century Psychology Series (pp. 1–451). New York: Appleton-Century. https://www.scribd.com/document/283214535/Skinner-B-F-1938-the-Behavior…
Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press. http://incompleteideas.net/book/RLbook2020.pdf
Thorndike, E. L. (1898). Animal intelligence: An experimental study of the associative processes in animals. The Psychological Review: Monograph Supplements, 2(4), i–109. https://doi.org/10.1037/h0092987
Tolman, E.C. (1948). Cognitive maps in rats and men. Psychological Review, 55(4), 189–208. https://doi.org/10.1037/h0061626
Verguts, T., & Storms, G. (2004). Assessing the informational value of parameter estimates in cognitive models. Behavior Research Methods, Instruments, & Computers, 36(1), 1-10.https://doi.org/10.3758/BF03195544
Wilcoxon, F. (1945) Individual Comparisons by Ranking Methods. Biometrics Bulletin, 1, 80-83. https://doi.org/10.2307/3001968
Wilson, R. C., Geana, A., White, J. M., Ludvig, E. A., & Cohen, J. D. (2014). Humans use directed and random exploration to solve the explore–exploit dilemma. Journal of Experimental Psychology: General, 143(6), 2074–2081. https://doi.org/10.1037/a0038199








