
Lang leve neologismen!
Tentsletje, moordstrookje, knaldrang of knuffelcontact. Ieder jaar ontstaan er duizenden nieuwe woorden, die we in de taalkunde "neologismen" noemen. Maar wat bepaalt het succes en de levensduur van nieuwe woorden?
Laat ons eerlijk zijn, wie gebruikt er in zijn dagelijkse taal nog het woord van het jaar 2016 samsonseks? De meeste nieuwe woorden zijn namelijk modegrillen en eendagsvliegen. Toch zijn er ook neologismen die wel lange tijd meegaan. Zo is het woord van het jaar 2013 selfie bijna niet meer weg te slaan uit onze woordenschat. De vraag die dan rijst is: zijn er bepaalde kenmerken die zorgen voor een hogere overlevingskans?
Een woord is als een dier?
De levensloop van een (nieuw) woord kan op verschillende manieren onderzocht en beschreven worden. Je kan bijvoorbeeld tellen hoe vaak een bepaald woord voorkomt in een corpus (een verzameling van teksten) en dat weergeven in een grafiek. Je kan het vergelijken met de populatie van een dier: een dier wordt geboren, doet de populatie stijgen, en sterft dan. Sommige dieren zijn met uitsterven bedreigd, andere kweken als konijnen. Bij woorden zien we gelijkaardige patronen terugkomen (Figuur 1). Die manier van werken focust echter vaak op individuele nieuwe woorden en hecht weinig aandacht aan de invloed van bepaalde kenmerken op het succes van neologismen op een overkoepelend niveau.
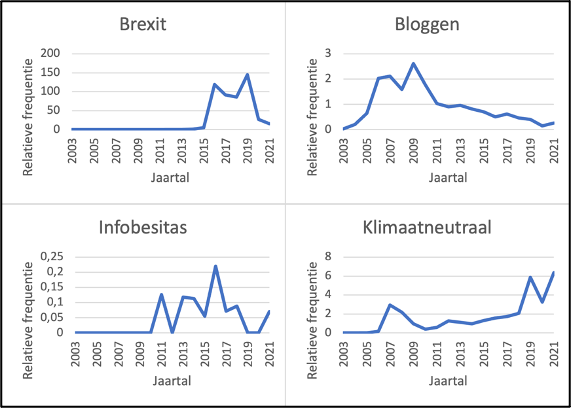
Figuur 1: Frequentieverlopen van een vaak voorkomend woord (Brexit), gemiddeld voorkomend woord (bloggen), weinig voorkomend woord (infobesitas) en een woord met zijn piek in zijn laatste levensjaar (klimaatneutraal).
Een andere werkwijze kijkt naar de overlevingskans van woorden. In plaats van te tellen hoe vaak een woord voorkomt, bekijkt zo'n analyse of een woord nog leeft na x-aantal jaar (Figuur 2). Deze methode komt uit de biologie en wordt bijvoorbeeld gebruikt om weer te geven wat de overlevingskans is van patiënten met een bepaalde ziekte na een behandeling.
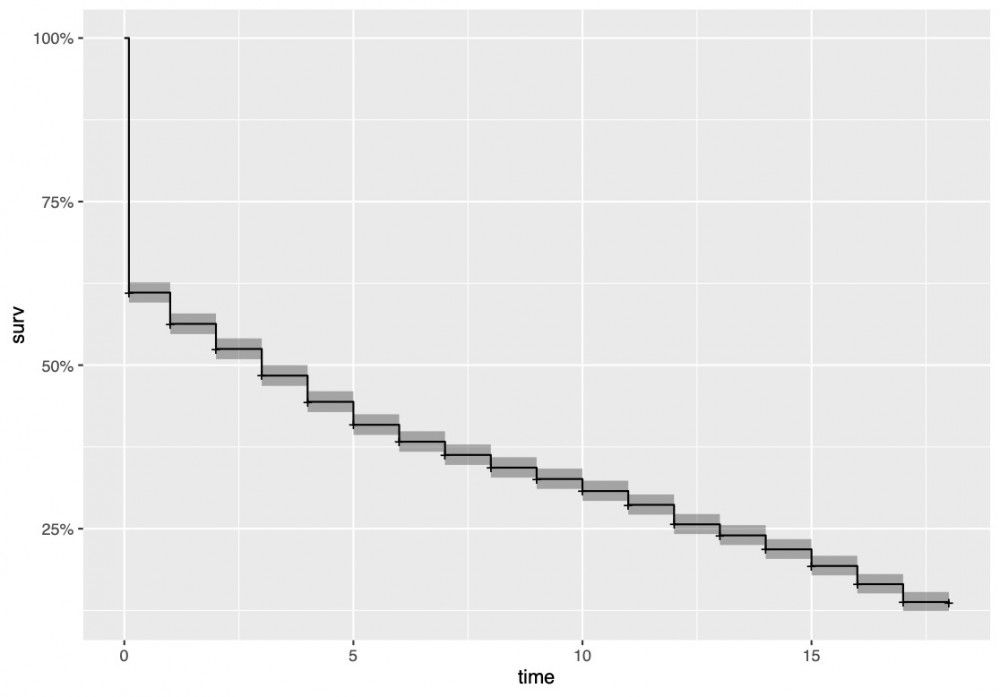
Figuur 2: Algemene overlevingscurve, die laat zien dat 39% van de neologismen sterft voor ze 1 jaar oud zijn.
Het voordeel van die methode is dat ze wel overkoepelend te werk gaat. Zulke analyses gaan in de taalkunde echter meestal over tijdspannen van meerdere eeuwen heen. Een overzicht van de overlevingskans van neologismen over enkele decennia, en welke kenmerken succes verzekeren, ontbreekt tot nu toe in het onderzoek naar neologismen, vooral in het Nederlands. Deze studie wil die leemte opvullen.
Onderzoeksopzet
Twee soorten bronnen werden gebruikt om de onderzoeksvraag te beantwoorden. Ten eerste werd een lijst van neologismen samengesteld door een combinatie van een Nederlands woordenboek met neologismen (WNW - Woordenboek van Nieuwe Woorden) en een databank van kandidaat-neologismen (Neoloog), wat resulteerde in 3804 neologismen "geboren" tussen 2000 en 2021. Ten tweede werd gekeken in een monitorcorpus (Corpus Hedendaags Nederlands) van wanneer tot wanneer die woorden voorkwamen. Dat corpus bevat kranten en magazines zoals De Standaard of NRC.
Die gegevens werden via een zelfgeschreven programma opgehaald en samengebracht in een Excelfile. Zo verkreeg ik drie kolommen: het neologisme, de leeftijd, en of het woord nog "leefde" in 2021. Naast die informatie volgden dan allerlei kolommen met kenmerken van die neologismen. De kenmerken die geacht werden een invloed te hebben zijn: bron (WNW vs. Neoloog), lengte, Levenshteinafstand (hoe uniek is een woord?), lidwoord, geslacht, woordsoort, woordvorming (samenstellingen), productiviteit, herkomst (leenwoorden vs. inheemse woorden), verspreiding, betekenisdomein, en synonymie. Die gegevens werden vervolgens geanalyseerd aan de hand van Kaplan Meier analyses en Cox Proportional Hazard modellen, twee statistische methoden om overlevingskansen te onderzoeken, in dit geval toegepast op nieuwe woorden.
Het succesrecept
De resultaten suggereren dat de drie kenmerken met de grootste invloed op het succes van een neologismen lengte, verspreiding en bron zijn. Qua lengte is het als neologisme erg voordelig als je niet te lang bent (Figuur 3). Lange woorden zijn namelijk moeilijker te onthouden dan korte. Bovendien hangt dit samen met het kenmerk woordvorming. Die curve toonde aan dat samenstellingen minder lang leven, zij zijn dan ook vaak langer dan woorden die geen samenstelling zijn.
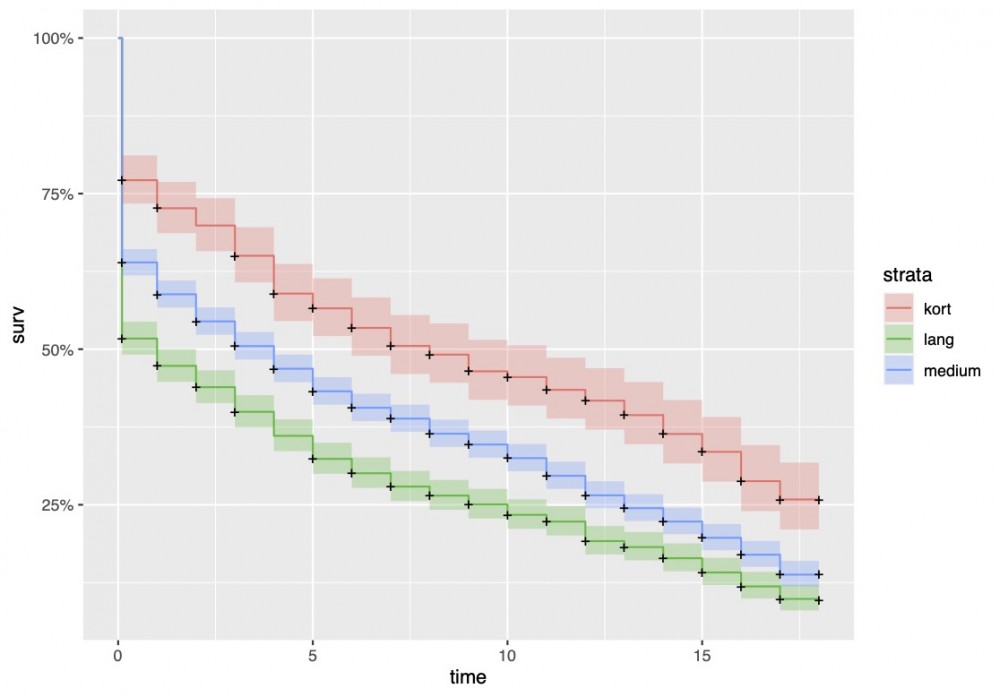
Figuur 3: Overlevingscurve met als kenmerk "lengte".
Verder speelt verspreiding een belangrijke rol in de overlevingskans van nieuwe woorden (Figuur 4). Neologismen die in beide variëteiten van het Nederlands voorkomen, hebben meer succes dan woorden die enkel in het Belgisch- of Nederlands-Nederlands opduiken. Bovendien zijn ook de woorden die eerst in het Nederlands-Nederlands voorkomen en dan in het Belgisch-Nederlands het succesvolst. Daaruit blijkt ook de grotere invloed van het Nederlands-Nederlands op de Nederlandse woordenschat.
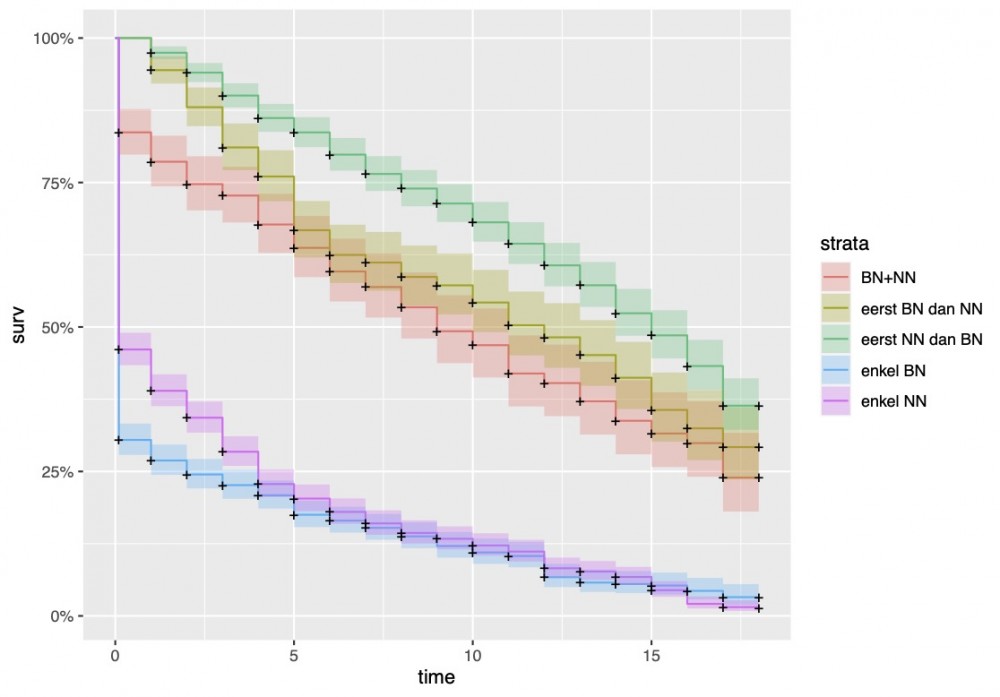
Figuur 4: Overlevingscurve met als kenmerk "verspreiding tussen Nederland en België".
De neologismen die in het woordenboek van nieuwe woorden zijn opgenomen, hebben ook een hogere overlevingskans dan zij die enkel in Neoloog staan. De lexicografen (woordenboekmakers) van het WNW hanteren dus goed voorspellende inclusiecriteria, en hun expertise draagt iets extra’s bij aan de overlevingskans van neologismen dat nog onbekend is.
Verder bleek dat werkwoorden langer leven dan zelfstandige naamwoorden en adjectieven. Neologismen die in het betekenisdomein "automatisering, informatie en communicatie" zitten hebben ook een hogere overlevingskans. Dat hangt samen met het feit dat dat vaak Engelse leenwoorden zijn, zoals podcast of Whatsapp. Daarvan is ook bewezen dat ze langer in onze woordenschat blijven.
Dit onderzoek kan lexicografen helpen bij het maken van weloverwogen keuzes om een neologisme al dan niet op te nemen in het woordenboek. Ook draagt dit onderzoek bij aan het beter begrijpen van de werking van taal in onze maatschappij. Onderzoekers, uitvinders, beleidsmakers die een naam aan iets nieuws willen geven weten nu welke kenmerken ervoor zorgen dat een woord blijft hangen.
Samenvattend kunnen we dus stellen dat het succesrecept voor een neologisme een kort woord is dat zowel in Nederland als België gebruikt wordt, en in het woordenboek terechtkomt.
Nu is het aan u om de theorie in de praktijk om te zetten en zelf het beste nieuwste woord van het jaar te verzinnen.
Bibliografie
Blom, W.B.T., Polisenska, D. & Weerman, F. (2008). Articles, adjectives and age of onset: the acquisition of Dutch grammatical gender. Second Language Research, 24(3), 297–331. https://doi.org/10.1177/0267658308090183.
Cartier, E. (2017). Neoveille, a Web Platform for Neologisme Tracking. Proceedings of the EACL 2017 Software Demonstrations, 95-98. https://doi.org/10.18653/v1/E17-3024.
Cornips, L. & De Vogelaer, G. (2009). Variatie en verandering in het Nederlandse genus: een multidisciplinair perspectief. Taal En Tongval, 61(1), 1–12. https://doi.org/10.5117/TET2009.1.CORN.
Corpus Hedendaags Nederlands - CHN (Versie 3.0) (Oktober 2021) [Online Service]. Beschikbaar bij het Insituut voor de Nederlandse Taal: http://hdl.handle.net/10032/tm-a2-s8. (Geraadpleegd op 30/12/2021).
De Vogelaer, G. (2006). Pronominaal genus bij “Zuid-Nederlandse” taalverwervers: van grammaticaal naar semantisch systeem. In Nederlands tussen Duits en Engels (pp. 89–102). Stichting Neerlandistiek Leiden.
Falk, I. Bernhard, D. & Gérard, C. (2018). The Logoscope: a Semi-Automatic Tool for Detecting and Documenting French New Words.
Freixa, J. & Torner, S. (2020). Beyond Frequency: On the Dictionarization of New Words in Spanish. Dictionaries: Journal of the Dictionary Society of North America 41(1), 131-153. doi:10.1353/dic.2020.0008.
Grieve, J., Nini, A. & Guo, D. (2017). Analyzing lexical emergence in Modern American English online. English Language and Linguistics, 21(1), 99–127. https://doi.org/10.1017/S1360674316000113.
Horikoshi, M. & Tang, Y. (2018). ggfortify: Data Visualization Tools for Statistical Analysis Results. https://CRAN.R-project.org/package=ggfortify.
Hulk, A. & Cornips, L. (2006). Neuter Gender and Interface Vulnerability in Child L2/2L1 Dutch. In PATHS OF DEVELOPMENT IN L1 AND L2 ACQUISITION: IN HONOR OF BONNIE D. SCHWARTZ, Unsworth, Sharon, Parodi, Teresa, Sorace, Antonella, & Young-Scholten, Martha [Eds], Amsterdam, NE: John Benjamins, 2006, pp 107-134.
Humboldt, W. Von. (2011). Über die Verschiedenheit des menschlichen Sprachbaues: und ihren Einfluß auf die geistige Entwickelung des Menschengeschlechts. Cambridge University Press.
INT ANW = Instituut voor de Nederlandse Taal (2021). Over het ANW.
https://anw.ivdnt.org/about (Geraadpleegd op 30/12/2021).
INT CHN = Instituut voor de Nederlandse Taal (2021). About the Corpus Hedendaags Nederlands (CHN). https://portal.clarin.inl.nl/corpus-frontend- chn/chnextern/about (Geraadpleegd op 30/12/2021).
INT WNW = Instituut voor de Nederlandse Taal (2021). Over het Woordenboek van Nieuwe Woorden. https://neologismen.ivdnt.org/about (Geraadpleegd op 30/12/2021).
Janssen, M. (2008). NeoTrack: Un analyseur de néologismes en ligne. In M.T. Cabré, O. Domènech, R. Estopà & J. Freixa (eds.) Proceedings of CINEO 2008, pp 1175-1188.
Jiang, M., Shen, X. Y., Ahrens, K. & Huang, C.-R. (2021). Neologisms are epidemic: Modeling the life cycle of neologisms in China 2008-2016. PloS One, 16(2), e0245984–e0245984. https://doi.org/10.1371/journal.pone.0245984.
Kassambara, A., Kosinski, M. & Biecek, P. (2019). survminer: drawing survival curves using ‘ggplot2’. R package version 0.4.6. https://CRAN.R- project.org/package=survminer.
Kehoe, A. & Gee, M. (2009). Weaving web data into a diachronic corpus patchwork. In Corpus Linguistics(Vol. 69, pp. 255–279). https://doi.org/10.1163/9789042025981_015.
Kerremans, D., Stegmayr, S. & Schmid, H.-J. (2011). The NeoCrawler: identifying and retrieving neologisms from the internet and monitoring ongoing change. In Current Methods in Historical Semantics (Vol. 73, pp. 59–96). DE GRUYTER. https://doi.org/10.1515/9783110252903.59.
Kerremans, D. (2015). A Web of New Words. A Corpus-Based Study of the Conventionalization Process of English Neologisms. English Corpus Linguistics 15.
Kerremans, D. & Prokić, J. (2018). Mining the Web for New Words: Semi-Automatic Neologism Identification with the NeoCrawler. Anglia (Tübingen), 136(2), 239– 268. https://doi.org/10.1515/ang-2018-0032.
Keuleers, E., Brysbaert, M. & New, B. (2010). SUBTLEX-NL: A new measure for Dutch word frequency based on film subtitles. Behavior Research Methods, 42(3), 643–650. https://doi.org/10.3758/BRM.42.3.643.
Klosa-Kückelhaus, A. & Wolfer, S. (2020). Considerations on the Acceptance of German neologisms from the 1990s. International Journal of Lexicography, 33(2), 150– 167. https://doi.org/10.1093/ijl/ecz033.
Kosem, I., Krek, S., Gantar, P., Holdt, S.A. & Čibej, J. (2021). Language Monitor: Tracking the Use of Words in Contemporary Slovene. Electronic Lexicography in the 21st Century (ELex 2021) Post-Editing Lexicography, 514-528.
Metcalf, A. (2002). Predicting New Words. The Secrets of their Success. Houghton Mifflin.
Nimb, S., Sørensen, N. H. & Lorentzen H. (2020). Updating the dictionary: Semantic change identification based on change in bigrams over time. Slovenščina 2.0, 8(2), 112-138. https://doi.org/10.4312/slo2.0.2020.2.112-138.
OLD20 = Keuleers, E. (2010). Fast computation of average Levenshtein distances. http://crr.ugent.be/programs-data/fast-computation-of-average-levenshte…; distances-in-python-including-old20. (Geraadpleegd op 31/05/2022).
Pollak, S., Gantar, P. & Arhar Holdt, Š. (2019). What's New on the Internetz? Extraction and Lexical Categorisation of Collocations in Computer-Mediated Slovene. International Journal of Lexicography, 32(2), 184–206. https://doi.org/10.1093/ijl/ecy026.
R Core Team (2020). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R- project.org/.
Renouf, A. (1993). A Word in Time: first findings from dynamic corpus investigation. In J. Aarts, P. de Haan, & N. Oostdijk (eds.) English Language Corpora: Design, Analysis and Exploitation, 279-288.
Renouf, A. (2009). Corpus Linguistics beyond Google: the WebCorp Linguist’s Search Engine. Digital Studies, 1(1). https://doi.org/10.16995/dscn.138
Renouf, A. (2013). A finer definition of neology in English: The life-cycle of a word. Studies in Corpus Linguistics, 57, 177–207. https://doi.org/10.1075/scl.57.14ren.
Schmid, H. (2008). New Words in the Mind: Concept-formation and Entrenchment of Neologisms. Anglia(Tübingen), 126(1), 1–36. https://doi.org/10.1515/angl.2008.002.
Therneau, T. (2022). A Package for Survival Analysis in R. R package version 3.3-1, https://CRAN.R-project.org/package=survival.
Trap-Jensen, L. (2020). Language-Internal Neologisms and Anglicisms: Dealing with New Words and Expressions in The Danish Dictionary. Dictionaries: Journal of the Dictionary Society of North America 41(1), 11-25.
Van der Sijs, N. (2002). Chronologisch woordenboek: De ouderdom en herkomst van onze woorden en betekenissen (2de dr. ed.).
Van de Velde, F. & Keersmaekers, A. (2020). What are the determinants of survival curves of words? An evolutionary linguistics approach. Evolutionary Linguistic Theory, 2(2), 127–137. https://doi.org/10.1075/elt.00019.vel.
Van de Velde, F. (2020). Zwindende Woorden. Op je Woorden Letten - 200 Jaar Matthias de Vries. Instituut voor de Nederlandse taal. https://www.facebook.com/ivdnt/videos/3274010056059652 (Geraadpleegd op 30/12/2021).
Van Geloven, N. & Geskus, R.B. (2018). Survival analyse. Wikistatistiek. Amsterdam UMC.https://wikistatistiek.amc.nl/index.php/Survival_analyse#Kaplan_Meier_a nalyse (Geraadpleegd op 08/02/2021).
Veale, T. (2006). Tracking the Lexical Zeitgeist with Wikipedia and WordNet. In Proceedings of ECAI’2006, the 17th European Conference on Artificial Intelligence, 56-60.
Waszink, V. (2016). Kraamkost, tabletbochels en lelijke groente: hoe zien nieuwe woorden eruit en wie gebruikt ze? Ons erfdeel, 59(3), 26-32.
Waszink, V. (2020). Neologisms in an Online Portal: The Dutch Neologismenwoordenboek (NW). Dictionaries: Journal of the Dictionary Society of North America 41(1), 27-44. doi:10.1353/dic.2020.0003.
Wickham, H. (2016). ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag, New York.
WNW = Instituut voor de Nederlandse Taal (2022). Woordenboek van Nieuwe Woorden. https://ivdnt.org/woordenboeken/nieuwe-woorden/. (Geraadpleegd op 19/05/2022).
Würschinger, Q. (2021). Social Networks of Lexical Innovation. Investigating the Social Dynamics of Diffusion of Neologisms on Twitter. Frontiers in Artificial Intelligence, 4, 648583–648583. https://doi.org/10.3389/frai.2021.648583.
Zenner, E., Speelman, D. & Geeraerts, D. (2012). Cognitive Sociolinguistics meets loanword research: Measuring variation in the success of anglicisms in Dutch. Cognitive Linguistics, 23(4), 749–792. https://doi.org/10.1515/cog- 2012-0023.






