Hoe Pentimentor jou kan ondersteunen bij het begrijpend lezen van wetenschappelijke artikelen.
Plaats jezelf in de schoenen van een scholier met dyslexie in de derde graad van het middelbaar onderwijs. Voor een opdracht begrijpend lezen moet jij de abstract uit een wetenschappelijk artikel doornemen, afgebeeld op onderstaande simulatie. Deze zelfgemaakte simulatie kan je op de volgende link terugvinden: https://dyashen.github.io/tryout-dyslexia-sim

Moeilijker dan je denkt? Onderschat de uitdaging niet! Hoewel symptomen van dyslexie niet alleen 'dansende letters' zijn, toont deze simulatie dat dit één van de obstakels is die dyslectische scholieren kunnen ervaren. Leerkrachten zouden de oorspronkelijke tekst in een andere lay-out kunnen gieten. Zo kunnen aangepaste lettertypes, woordspatiëring of regelafstand het lezen van een artikel aangenamer maken voor een scholier met dyslexie.
Bovendien vereist het lezen van wetenschappelijke artikelen specifieke vakkennis. Deze artikelen kunnen scholieren in de derde graad van het middelbaar onderwijs sterker motiveren om hun opleiding verder te zetten in het hoger onderwijs. Het begrijpen van tekstinhoud kan echter een lastige taak zijn. De oplossing hiervoor: tekstvereenvoudiging. Door de woordenschat en zinsbouw aan te passen, maken auteurs deze artikelen opnieuw toegankelijk voor een lager wetenschappelijk geletterde doelgroep. De afbeelding hieronder toont deze veranderingen, maar deze zelfgemaakte simulatie kan u online hier terugvinden: https://dyashen.github.io/tryout-dyslexia-sim-start
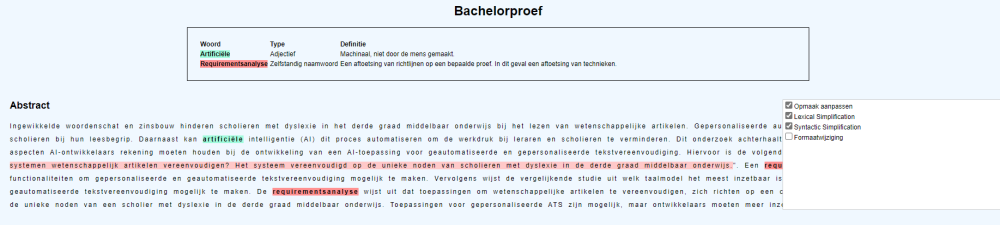
De uitdaging met personaliseerbare tekstvereenvoudiging
Personaliseerbare tekstvereenvoudiging heeft een bewezen effect op het leereffect van scholieren in het middelbaar onderwijs, maar dit proces vraagt tijd en energie van de auteur.
Toepassingen voor tekstvereenvoudiging bestaan al, maar ze ontbreken de nodige personaliseerbaarheid en veranderen de moeilijkheidsgraad van de oorspronkelijke tekst niet. Daarnaast beschikken software-ontwikkelaars over onvoldoende logopedische voorkennis om deze toepassingen te ontwikkelen. Bovendien kan dergelijke toepassing iedereen in het onderwijs baten. Om te bewijzen dat ontwikkelaars hier wél met de huidige middelen toe in staat zijn, ontwikkelde dit onderzoek een prototype: Pentimentor.
Pentimentor: het nieuwste van het nieuwste
Pentimentor is een prototype om pdf-documenten te vereenvoudigen en samen te vatten. Allereerst kan je op een aanpasbare webpagina het oorspronkelijke wetenschappelijke artikel lezen. In deze omgeving kan je delen tekst in het artikel markeren, zodat je deze vervolgens kan laten vereenvoudigen of samenvatten door Pentimentor. Daarnaast kan je ook specifieke vragen stellen over de inhoud van de gemarkeerde tekst. Tot slot biedt Pentimentor de mogelijkheid om een nieuw Word-document te genereren met daarin de vereenvoudigde tekst.
Om tekstaanpassingen in deze mate mogelijk te maken, gebruikt Pentimentor het GPT-3 model. Als die naam je bekend in de oren klinkt, dan is dat geen toeval, want dit is het achterliggende taalmodel van ChatGPT. Maar waarom specifiek dit taalmodel? GPT-3 kan personaliseerbare uitvoer genereren. Afhankelijk van jouw keuzes kan het vereenvoudigde document anders zijn dan dat van andere gebruikers.
Het is mogelijk om voor de lezer ongekende woorden mee te geven. Nadien vereenvoudigt het taalmodel, wat niet mogelijk is bij andere toepassingen op de markt. Dit prototype probeert de achtergrondkennis van de eindgebruiker goed in te schatten. Daarmee laat het prototype geen gekende kennis achterwege en kan het een merkbaar leereffect aanreiken.
Keep it simple
Ontwikkelaars maken graag indruk met hun toepassingen. Bestaande toepassingen die teksten kunnen samenvatten of vereenvoudigen, zijn overladen met functies, waardoor gebruikers het overzicht kwijtraken. Daarom richt Pentimentor zich op eenvoud. Hier kunnen gebruikers kiezen hoe het systeem de wetenschappelijke inhoud weergeeft of verandert, op manieren die andere systemen niet kunnen. Hierdoor maakt het prototype alle voorgaande toepassingen overbodig. Zo toont de onderstaande afbeelding hoe Pentimentor op een eenduidige manier ondersteuning aan scholieren kan bieden. Scholieren kunnen teksten op maat laten herschrijven, vragen stellen over de tekst of (moeilijke) woorden aanduiden. Deze komen in een woordenlijst terecht die zij kunnen laten weergeven of verbergen.
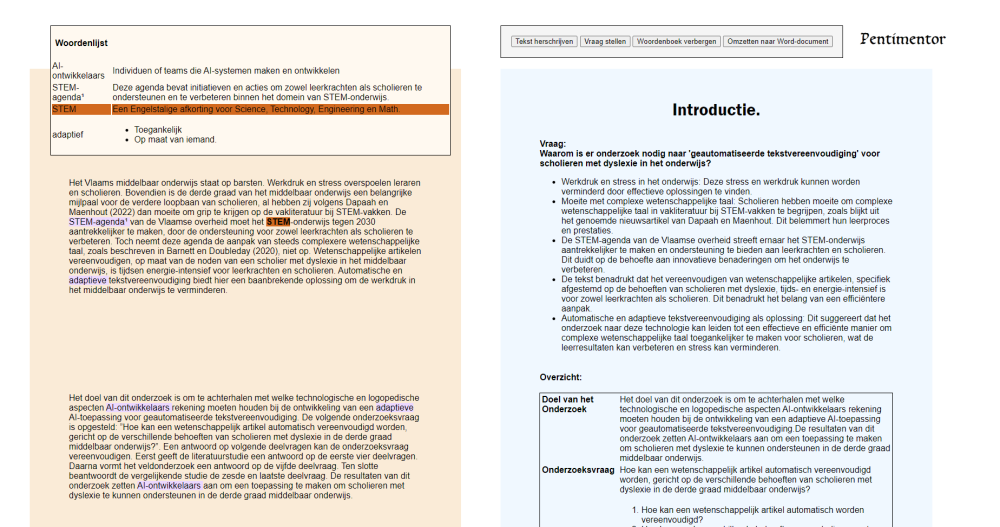
Na het maken van Pentimentor vergeleek ik dit met andere tools die ook functionaliteiten voor tekstvereenvoudiging of samenvatten aanreiken. Uit een vergelijkende studie blijkt dat Pentimentor duidelijk boven andere tools staat. Zo ontbreekt personaliseerbaarheid in de uitgeteste tools. De uitvoer is identiek bij iedere eindgebruiker. Daarnaast kunnen deze tools geen wetenschappelijke concepten samenvatten in een overzichtelijke vorm, zoals een tabel.
De presentatie van het artikel is enkel een bijzaak bij de andere tools. Pentimentor houdt hier wel rekening mee door het oorspronkelijke en het vereenvoudigde artikel op één personaliseerbare pagina te tonen. Dit speelt een rol bij scholieren met leesstoornissen, waaronder dyslexie. Geen enkele toepassing is in staat om een Word-document te maken, terwijl Pentimentor dit wel kan. Zo kan de eindgebruiker nog zaken, zoals lay-out, aanpassen indien nodig.
Ten slotte kan Pentimentor duidelijk de link met het oorspronkelijke artikel leggen. Andere toepassingen doen dit niet en verwachten dat de eindgebruiker deze zelf kan leggen. Bij dergelijke toepassingen ligt de focus te weinig op de relatie tussen de oorspronkelijke en aangepaste tekst. Pentimentor zet ontwikkelaars hiertoe aan.
Tot slot
Is Pentimentor de ultieme ondersteuning voor het begrijpend lezen van wetenschappelijke artikelen bij scholieren? Nog niet.
Hoewel Pentimentor veelbelovende teksten kan schrijven, bevindt het zich nog in de prototypefase en vereist het verdere ontwikkeling. Software-ontwikkelaars beschikken wel degelijk over de nodige middelen om het concept concreet uit te werken. Zo kunnen zij teksten laten herschrijven met het GPT-3 taalmodel zonder dat ze zelf een taalmodel moeten ontwikkelen. Als je Pentimentor zelf wil uittesten, kan je het installeren volgens de instructies op deze link: https://github.com/Dyashen/pentimentor/
Bibliografie
Althunayyan, S. & Azmi, A. (2021). Automated Text Simplification: A Survey. ACM
Computing Surveys, 54, Article no. 43. https://doi.org/10.1145/3442695
Ball, P. (2017). It’s not just you: science papers are getting harder to read. Nature.
Barnett, A. & Doubleday, Z. (2020). Meta-Research: The growth of acronyms in the
scientific literature (P. Rodgers, Red.). eLife, 9, e60080.
Belpaeme, T., Kennedy, J., Ramachandran, A., Scassellati, B. & Tanaka, F. (2018). Social
robots for education: A review. Science robotics, 3(21), eaat5954.
Bezem, A. & Lugthart, M. (2016). Visuele Disfunctie een onzichtbare belemmering
bij lezen, spelling en concentratie. https://beeldenbrein.nl/
Bilici, Ş. (2021). Sequence labeling.
Bingel, J., Paetzold, G. & Søgaard, A. (2018). Lexi: A tool for adaptive, personalized text
simplification. Proceedings of the 27th International Conference on Computational
Linguistics, 245–258.
Binz, M. & Schulz, E. (2023). Using cognitive psychology to understand GPT-3. Proceedings
of the National Academy of Sciences, 120(6).
Bonte, M. (2020). Bestaat Dyslexie?: En is het een relevante vraag? uitgeverij SWP.
Bosmans, A., Croon, S. & Verreycken, V. (2022a). Woordgebruik - Moeilijke constructies.
https://www.vlaanderen.be/taaladvies/taaladviezen/teksten-schrijven/
formulering/zinsbouw-moeilijke-constructies
Bosmans, A., Croon, S. & Verreycken, V. (2022b). Woordgebruik - Moeilijke Woorden.
https : / / www . vlaanderen . be / taaladvies / taaladviezen / teksten - schrijven /
formulering/woordgebruik-moeilijke-woorden
Bosmans, A., Croon, S. & Verreycken, V. (2022c). Woordgebruik - Synoniemen. https://
www.vlaanderen.be/taaladvies/taaladviezen/teksten-schrijven/formulering/
woordgebruik-synoniemen
Botelho, F. H. F. (2021). Accessibility to digital technology: Virtual barriers, real opportunities
[PMID: 34951832]. Assistive Technology, 33(sup1), 27–34. https://
doi.org/10.1080/10400435.2021.1945705
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan,
A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G.,
Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., … Amodei,
D. (2020). Language Models are Few-Shot Learners.
Bulté, B., Sevens, L. & Vandeghinste, V. (2018). Automating lexical simplification in
Dutch. Computational Linguistics in the Netherlands Journal, 8, 24–48. https:
//clinjournal.org/clinj/article/view/78
Canning, Y., Tait, J., Archibald, J. & Crawley, R. (2000). Cohesive Generation of Syntactically
Simplified Newspaper Text. In P. Sojka, I. Kopeček & K. Pala (Red.),
Text, Speech and Dialogue (pp. 145–150). Springer Berlin Heidelberg.
Cantos, P. & Almela, Á. (2019). Readability indices for the assessment of textbooks: a
feasibility study in the context of EFL. Vigo International Journal of Applied
Linguistics, 31–52. https://doi.org/10.35869/vial.v0i16.92
Cao, M. (2022). A Survey on Neural Abstractive Summarization Methods and Factual
Consistency of Summarization.
Charlesworth Author Services. (2021). https://www.cwauthors.com/article/How-towrite-
about-complex-scientific-concepts-in-simple-accessible-language
Chowdhary, K. (2020). Fundamentals of Artificial Intelligence. Springer, New Delhi.
Coster, W. & Kauchak, D. (2011). Learning to Simplify Sentences Using Wikipedia.
Proceedings of the Workshop on Monolingual Text-To-Text Generation, 1–9.
https://aclanthology.org/W11-1601
Crevits, H. (2022, maart 13). Kwart van bedrijven gebruikt artificiële intelligentie:
Vlaanderen bij beste leerlingen van de klas (Persbericht). Vlaamse Overheid
Departement Economie, Wetenschap en Innovatie.
Crossley, S. A., Allen, D. & McNamara, D. S. (2012). Text simplification and comprehensible
input: A case for an intuitive approach. Language Teaching Research,
16(1), 89–108.
Crossley, S. A., Skalicky, S. & Dascalu, M. (2019). Moving beyond classic readability
formulas: new methods and new models. Journal of Research in Reading,
42(3-4), 541–561. https://doi.org/https://doi.org/10.1111/1467-9817.12283
Dandekar, N. (2016). How to use machine learning to find synonyms. https://medium.
com/@nikhilbd/how-to-use-machine-learning-to-find-synonyms-6380c0c6106b
Dapaah, J. & Maenhout, K. (2022, juli 8). Iedereen heeft boter op zijn hoofd (D. Standaard,
Red.). https://www.standaard.be/cnt/dmf20220607_97763592
De Craemer, J., Van Beeumen, L., Cooreman, A., Moonen, A., Rottier, J., Wagemakers,
I. & Mardulier, T. (2018). Aan de slag met voorleessoftware op school.
Een gids met 8 vragen en antwoorden. https : / / onderwijs . vlaanderen . be /
nl/onderwijspersoneel/van-basis-tot-volwassenenonderwijs/lespraktijk/ictin-
de-klas/voorleessoftware-voor-leerlingen-met-leesbeperkingen/aan-deslag-
met-voorleessoftware-op-school
De Meyer, I., Janssens, R. & Warlop, N. (2019). Leesvaardigheid van 15- jarigen in
Vlaanderen: Overzicht van de eerste resultaten van PISA2018. https://dataonderwijs.
vlaanderen.be/documenten/bestand.ashx?id=12265
Deckmyn, D. (2021, maart 19). Robot schrijft mee De Standaard (D. Standaard, Red.).
https://www.standaard.be/cnt/dmf20210319_05008561
Departement onderwijs en vorming. (2023). Voorleessoftware voor Leerlingen met
Leesbeperkingen. https://onderwijs.vlaanderen.be/voorleessoftware- voorleerlingen-
met-leesbeperkingen
Donato, A., Muscolo, M., Arias Romero, M., Caprì, T., Calarese, T. & Olmedo Moreno,
E. M. (2022). Students with dyslexia between school and university: Post-diploma
choices and the reasons that determine them. An Italian study. Dyslexia,
28(1), 110–127.
DuBay, W. H. (2004). The principles of readability. Online Submission.
Eisenstein, J. (2019). Introduction to Natural Language Processing. MIT Press. https:
//books.google.be/books?id=72yuDwAAQBAJ
Fabbri, A. R., Kryściński, W., McCann, B., Xiong, C., Socher, R. & Radev, D. (2020). SummEval:
Re-evaluating Summarization Evaluation.
Gala, N. & Ziegler, J. (2016). Reducing lexical complexity as a tool to increase text accessibility
for children with dyslexia. Proceedings of the Workshop on Computational
Linguistics for Linguistic Complexity (CL4LC), 59–66.
Galliussi, J. e.a. (2020). Inter-letter spacing, inter-word spacing, and font with dyslexiafriendly
features: testing text readability in people with and without dyslexia.
Annals of Dyslexia, 70, 141–152.
Garbacea, C., Guo, M., Carton, S. & Mei, Q. (2021). Explainable Prediction of Text Complexity:
The Missing Preliminaries for Text Simplification. Proceedings of the
59th Annual Meeting of the Association for Computational Linguistics and
the 11th International Joint Conference on Natural Language Processing
(Volume 1: Long Papers), 1086–1097. https : / / doi . org / 10 . 18653 / v1 / 2021 . acl -
long.88
Garg, H. (2022). Using GPT-3 for education: Use cases. https://indiaai.gov.in/article/
using-gpt-3-for-education-use-cases
Ghesquière, P. (2018). Als leren pijn doet: Kinderen met een leerstoornis opvoeden
en begeleiden. Acco.
Gooding, S. (2022). On the Ethical Considerations of Text Simplification. Ninth Workshop
on Speech and Language Processing for Assistive Technologies (SLPAT-
2022), 50–57. https://doi.org/10.18653/v1/2022.slpat-1.7
Gooding, S. & Kochmar, E. (2019). Complex word identification as a sequence labelling
task. Proceedings of the 57th Annual Meeting of the Association for
Computational Linguistics, 1148–1153.
Greg, B., Atty, E., Elie, G., Joane, J., Logan, K., Lim, R., Luke, M. & Michelle, P. (2023). Introducing
chatgpt and Whisper Apis. https://openai.com/blog/introducingchatgpt-
and-whisper-apis
Gupta, S. & Gupta, S. K. (2019). Abstractive summarization: An overview of the state
of the art. Expert Systems with Applications, 121, 49–65. https://doi.org/https:
//doi.org/10.1016/j.eswa.2018.12.011
Hahn, U. & Mani, I. (2000). The Challenges of Automatic Summarization. Computer,
33, 29–36. https://doi.org/10.1109/2.881692
Hartley, J. (1999). From Structured Abstracts to Structured Articles: A Modest Proposal.
Journal of Technical Writing and Communication, 29(3), 255–270. https:
//doi.org/10.2190/3RWW-A579-HC8W-6866
Harwell, D. (2023). Tech’s hottest new job: Ai whisperer. no coding required. https:
//www.washingtonpost.com/technology/2023/02/25/prompt- engineerstechs-
next-big-job/
Hayes, D. P. (1992). The growing inaccessibility of science. https://www.nature.com/
articles/356739a0
Hern, A. (2023). TechScape: Will meta’s massive leak democratise AI – and at what
cost? https://www.theguardian.com/technology/2023/mar/07/techscapemeta-
leak-llama-chatgpt-ai-crossroads
Hollenkamp, J. (2020). Summary and analysis of Scientific Research Articles - San
Jose State ... https://www.sjsu.edu/writingcenter/docs/handouts/Summary%
20and%20Analysis%20of%20Scientific%20Research%20Articles.pdf
Hsu, W.-T., Lin, C.-K., Lee, M.-Y., Min, K., Tang, J. & Sun, M. (2018). A Unified Model for
Extractive and Abstractive Summarization using Inconsistency Loss.
Huang, S., Wang, R., Xie, Q., Li, L. & Liu, Y. (2019). An Extraction-Abstraction Hybrid
Approach for Long Document Summarization. 2019 6th International Conference
on Behavioral, Economic and Socio-Cultural Computing (BESC), 1–
6.
Hubbard, K. E. & Dunbar, S. D. (2017). Perceptions of scientific research literature
and strategies for reading papers depend on academic career stage. PLOS
ONE, 12(12), 1–16.
Iavarone, B., Brunato, D. & Dell’Orletta, F. (2021). Sentence Complexity in Context.
Proceedings of the Workshop on Cognitive Modeling and Computational
Linguistics, 186–199. https://doi.org/10.18653/v1/2021.cmcl-1.23
IBM. (2022). IBM Global AI Adoption Index 2022. https://www.ibm.com/downloads/
cas/GVAGA3JP
Iredale, G. (2022). An overview of tokenization algorithms in NLP. https://101blockchains.
com/tokenization-nlp/
Iskender, N., Polzehl, T. & Möller, S. (2021). Reliability of Human Evaluation for Text
Summarization: Lessons Learned and Challenges Ahead. Proceedings of the
Workshop on Human Evaluation of NLP Systems (HumEval), 86–96. https:
//aclanthology.org/2021.humeval-1.10
Javourey-Drevet, L., Dufau, S., François, T., Gala, N., Ginestié, J. & Ziegler, J. C. (2022).
Simplification of literary and scientific texts to improve reading fluency and
comprehension in beginning readers of French. Applied Psycholinguistics,
43(2), 485–512. https://doi.org/10.1017/S014271642100062X
Jiang, R. K. (2023). Prompt engineering : Deconstructing and managing intention.
https : / / www . linkedin . com / pulse / prompt - engineering - deconstructing -
managing-intention-jiang/
Jones, R., Colusso, L., Reinecke, K. & Hsieh, G. (2019). r/science: Challenges and Opportunities
in Online Science Communication. CHI ’19: Proceedings of the
2019 CHI Conference on Human Factors in Computing Systems, 1–14. https:
//doi.org/10.1145/3290605.3300383
Jurafsky, D., Martin, J., Norvig, P. & Russell, S. (2014). Speech and Language Processing.
Pearson Education. https://books.google.be/books?id=Cq2gBwAAQBAJ
Kandula, S., Curtis, D. & Zeng-Treitler, Q. (2010). A semantic and syntactic text simplification
tool for health content. AMIA annual symposium proceedings, 2010,
366.
Khan, A. (2014). A Review on Abstractive Summarization Methods. Journal of Theoretical
and Applied Information Technology, 59, 64–72.
Khurana, D., Koli, A., Khatter, K. & Singh, S. (2022). Natural Language Processing:
State of The Art, Current Trends and Challenges. Multimedia Tools and Applications,
82, 25–27.
Kraft, M. A. (2020). Interpreting Effect Sizes of Education Interventions. Educational
Researcher, 49(4), 241–253. https://doi.org/10.3102/0013189X20912798
Lee, J. (2021). Extract text from unsearchable pdfs for data analysis using Python.
https://medium.com/social-impact-analytics/extract-text-from-unsearchab…-
for-data-analysis-using-python-a6a2ca0866dd
Leroy, G., Kauchak, D. & Mouradi, O. (2013). A user-study measuring the effects of
lexical simplification and coherence enhancement on perceived and actual
text difficulty. International Journal of Medical Informatics, 82(8), 717–730.
https://doi.org/https://doi.org/10.1016/j.ijmedinf.2013.03.001
Li, C. (2022). OpenAI’s GPT-3 language model: A technical overview. https://lambdalabs.
com/blog/demystifying-gpt-3
Li, J., Sun, A., Han, J. & Li, C. (2018). A Survey on Deep Learning for Named Entity
Recognition.
Lin, H. & Bilmes, J. (2010). Multi-document summarization via budgeted maximization
of submodular functions. Human Language Technologies: The 2010
Annual Conference of the North American Chapter of the Association for
Computational Linguistics, 912–920.
Linderholm, T., Everson, M. G., van den Broek, P., Mischinski, M., Crittenden, A. & Samuels,
J. (2000). Effects of Causal Text Revisions on More- and Less-Skilled
Readers’ Comprehension of Easy and Difficult Texts. Cognition and Instruction,
18(4), 525–556.
Lissens, F., Asmar, M., Willems, D., Van Damme, J., De Coster, S., Demeestere, E.,
Maes, R., Baccarne, B., Robaeyst, B., Duthoo, W. & Desoete, A. (2020). Het stopt
nooit…De impact van dyslexie en/of dyscalculie op het welbevinden en studeren
van (jong)volwassenen en op de transitie naar de arbeidsmarkt: een
bundeling van Vlaamse pilootstudies.
Liu, Q., Kusner, M. J. & Blunsom, P. (2020). A Survey on Contextual Embeddings.
Malik, R. S. (2022, juli 4). Top 5 NLP Libraries To Use in Your Projects (T. AI, Red.).
https://towardsai.net/p/l/top-5-nlp-libraries-to-use-in-your-projects
Martens, M., De Wolf, R. & Evens, T. (2021a). Algoritmes en AI in de onderwijscontext:
Een studie naar de perceptie, mening en houding van leerlingen en ouders
in Vlaanderen. Kenniscentrum Data en Maatschappij. Verkregen 30 maart
2022, van https://data- en- maatschappij.ai/publicaties/survey- onderwijs-
2021
Martens, M., De Wolf, R. & Evens, T. (2021b, juni 28). School innovation forum 2021.
Kenniscentrum Data en Maatschappij. Verkregen 1 april 2022, van https : / /
data-en-maatschappij.ai/nieuws/school-innovation-forum-2021
Matarese, V. (2013). 5 - Using strategic, critical reading of research papers to teach
scientific writing: the reading–research–writing continuum. In V. Matarese
(Red.), Supporting Research Writing (pp. 73–89). Chandos Publishing. https:
//doi.org/https://doi.org/10.1016/B978-1-84334-666-1.50005-9
McDonald, R. (2007). A study of global inference algorithms in multi-document
summarization. Advances in Information Retrieval: 29th European Conference
on IR Research, ECIR 2007, Rome, Italy, April 2-5, 2007. Proceedings
29, 557–564.
McFarland, A. (2023). What is prompt engineering in AI amp; Why It Matters. https:
//www.unite.ai/what-is-prompt-engineering-in-ai-why-it-matters/
McKeown, K., Klavans, J. L., Hatzivassiloglou, V., Barzilay, R. & Eskin, E. (1999). Towards
multidocument summarization by reformulation: Progress and prospects.
McNutt, M. (2014). Reproducibility. Science, 343(6168), 229–229. https://doi.org/10.
1126/science.1250475
Menzli, A. (2023). Tokenization in NLP: Types, challenges, examples, tools. https : / /
neptune.ai/blog/tokenization-in-nlp
Miszczak, P. (2023). Prompt engineering: The ultimate guide 2023 [GPT-3 amp; chatgpt].
https://businessolution.org/prompt-engineering/
Mottesi, C. (2023). GPT-3 vs. Bert: Comparing the two most popular language models.
https://blog.invgate.com/gpt-3-vs-bert
Nallapati, R., Zhai, F. & Zhou, B. (2017). SummaRuNNer: A Recurrent Neural Network
Based Sequence Model for Extractive Summarization of Documents
Proceedings of the AAAI Conference on Artificial Intelligence, 31(1). https://
doi.org/10.1609/aaai.v31i1.10958
Nandhini, K. & Balasundaram, S. (2013). Improving readability through extractive
summarization for learners with reading difficulties. Egyptian Informatics
Journal, 14(3), 195–204.
Nenkova, A. & Passonneau, R. (2004). Evaluating Content Selection in Summarization:
The Pyramid Method. Proceedings of the Human Language Technology
Conference of the North American Chapter of the Association for Computational
Linguistics: HLT-NAACL 2004, 145–152.
Niemeijer, A., Frederiks, B., Riphagen, I., Legemaate, J., Eefsting, J. & Hertogh, C.
(2010). Ethical and practical concerns of surveillance technologies in residential
care for people with dementia or intellectual disabilities: an overview
of the literature. Psychogeriatrics, 22(7), 1129–1142. https : / / doi . org / 10 . 1017 /
S1041610210000037
Onderwijsinspectie Overheid Vlaanderen. (2020). https : / / www . vlaanderen . be /
publicaties / begrijpend - leesonderwijs - in - de - basisscholen - kwaliteitsvol -
sterke-en-zwakke-punten-van-de-huidige-praktijk
Paetzold, G. & Specia, L. (2016). SemEval 2016 Task 11: Complex Word Identification.
Proceedings of the 10th International Workshop on Semantic Evaluation
(SemEval-2016), 560–569. https://doi.org/10.18653/v1/S16-1085
Pain, E. (2016). How to (seriously) read a scientific paper. https://www.science.org/
content/article/how-seriously-read-scientific-paper
Plavén-Sigray, P., Matheson, G. J., Schiffler, B. C. & Thompson, W. H. (2017). Research:
The readability of scientific texts is decreasing over time (S. King, Red.). eLife,
6, e27725.
Poel, M., Boschman, E. & op den Akker, R. (2008). A Neural Network Based Dutch
Part of Speech Tagger [http://eprints.ewi.utwente.nl/14662 ; 20th Benelux Conference
on Artificial Intelligence, BNAIC 2008, BNAIC ; Conference date: 30-
10-2008 Through 31-10-2008]. In A. Nijholt, M. Pantic, M. Poel & H. Hondorp
(Red.), BNAIC 2008 (pp. 217–224). Twente University Press (TUP).
Premjith, P., John, A. & Wilscy, M. (2015). Metaheuristic Optimization Using Sentence
Level Semantics for Extractive Document Summarization, 347–358. https://
doi.org/10.1007/978-3-319-26832-3_33
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I. e.a. (2019). Language
models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
Rani, R. & Kaur, B. (2021). The TEXT SUMMARIZATION AND ITS EVALUATION TECHNIQUE.
Turkish Journal of Computer and Mathematics Education (TURCOMAT),
12(1), 745–752.
Readable. (2021). Flesch Reading Ease and the Flesch Kincaid Grade Level. https:
//readable.com/readability/flesch-reading-ease-flesch-kincaid-grade-level/
Rello, L. & A. Baeza-Yates, R. (2015). How to present more readable text for people
with dyslexia. Universal Access in the Information Society, 16, 29–49.
Rello, L. & Baeza-Yates, R. (2013). Good fonts for dyslexia. Proceedings of the 15th
International ACM SIGACCESS Conference on Computers and Accessibility,
ASSETS 2013.
Rello, L., Baeza-Yates, R., Bott, S. & Saggion, H. (2013). Simplify or Help? Text Simplification
Strategies for People with Dyslexia. Proceedings of the 10th International
Cross-Disciplinary Conference on Web Accessibility. https://doi.org/10.
1145/2461121.2461126
Rello, L., Baeza-Yates, R., Dempere-Marco, L. & Saggion, H. (2013). Frequent Words
Improve Readability and Short Words Improve Understandability for People
with Dyslexia.
Rello, L., Baeza-Yates, R. & Saggion, H. (2013). The Impact of Lexical Simplification by
Verbal Paraphrases for People with and without Dyslexia. 7817, 501–512.
Rello, L. & Bigham, J. (2017). Good Background Colors for Readers: A Study of People
with and without Dyslexia, 72–80.
Rello, L., Kanvinde, G. & Baeza-Yates, R. (2012a). Layout Guidelines for Web Text and
a Web Service to Improve Accessibility for Dyslexics. Proceedings of the International
Cross-Disciplinary Conference on Web Accessibility.
Rello, L., Kanvinde, G. & Baeza-Yates, R. (2012b). Layout Guidelines for Web Text and
a Web Service to Improve Accessibility for Dyslexics. Proceedings of the International
Cross-Disciplinary Conference on Web Accessibility.
Ribas, J. (2023). Building the new bing. https://www.linkedin.com/pulse/buildingnew-
bing-jordi-ribas/
Ribeiro, E., Ribeiro, R. & de Matos, D. M. (2018). A Study on Dialog Act Recognition
using Character-Level Tokenization.
Rijkhoff, J. (2022). Tekst Inkorten?: 9 tips om Je Teksten korter Te Maken. https : / /
dialoogtrainers.nl/tekst-inkorten-tips/
Rivero-Contreras, M., Engelhardt, P. E. & Saldaña, D. (2021). An experimental eyetracking
study of text adaptation for readers with dyslexia: effects of visual
support and word frequency. Annals of Dyslexia, 71, 170–187.
Roldós, I. (2020, december 22). Major Challenges of Natural Language Processing
(NLP). MonkeyLearn. Verkregen 1 april 2022, van https://monkeylearn.com/
blog/natural-language-processing-challenges/
Roose, K. (2023). Don’t ban chatgpt in schools. teach with it. https://www.nytimes.
com/2023/01/12/technology/chatgpt-schools-teachers.html
Ruelas Inzunza, E. (2020). Reconsidering the Use of the Passive Voice in Scientific
Writing. The American Biology Teacher, 82, 563–565. https://doi.org/10.1525/
abt.2020.82.8.563
Santana, V., Oliveira, R., Almeida, L. & Baranauskas, M. C. (2012). Web accessibility
and people with dyslexia: A survey on techniques and guidelines. W4A 2012
- International Cross-Disciplinary Conference on Web Accessibility. https://
doi.org/10.1145/2207016.2207047
Sciforce. (2020, februari 4). Biggest Open Problems in Natural Language Processing.
Verkregen 1 april 2022, van https://medium.com/sciforce/biggest-openproblems-
in-natural-language-processing-7eb101ccfc9
Shardlow, M. (2013). A Comparison of Techniques to Automatically Identify Complex
Words. 51st Annual Meeting of the Association for Computational Linguistics
Proceedings of the Student Research Workshop, 103–109. https : / /
aclanthology.org/P13-3015
Shardlow, M. (2014). A Survey of Automated Text Simplification. International Journal
of Advanced Computer Science and Applications(IJACSA), Special Issue
on Natural Language Processing 2014, 4(1). https://doi.org/10.14569/SpecialIssue.
2014.040109
Shen, Z., Zhang, R., Dell, M., Lee, B. C. G., Carlson, J. & Li, W. (2021). LayoutParser: A
Unified Toolkit for Deep Learning Based Document Image Analysis. arXiv
preprint arXiv:2103.15348.
Siddharthan, A. (2006). Syntactic Simplification and Text Cohesion. Research on
Language and Computation, 4(1), 77–109. http://oro.open.ac.uk/58888/
Siddharthan, A. (2014). A survey of research on text simplification. ITL - International
Journal of Applied Linguistics, 165, 259–298.
Sikka, P. & Mago, V. (2020). A Survey on Text Simplification. CoRR, abs/2008.08612.
https://arxiv.org/abs/2008.08612
Simon, J. (2021). Large language models: A new moore’s law? https://huggingface.
co/blog/large-language-models
Sleuwaegen, L. (2022). Nederland versus België:nbsp; verschillen in economischenbsp;
dynamiek en beleid. https://feb.kuleuven.be/research/les/pdf/LES%202022%
20-%20197.pdf
Snow, C. (2010). Academic Language and the Challenge of Reading for Learning
About Science. Science (New York, N.Y.), 328, 450–2.
Sohom, G., Ghosh; Dwight. (2019). Natural Language Processing Fundamentals.
Packt Publishing. https://medium.com/analytics-vidhya/natural-languageprocessing-
basic-concepts-a3c7f50bf5d3
Stajner, S. (2021). Automatic Text Simplification for Social Good: Progress and Challenges,
2637–2652. https://doi.org/10.18653/v1/2021.findings-acl.233
Strubell, E., Ganesh, A. & McCallum, A. (2019). Energy and Policy Considerations for
Deep Learning in NLP.
Suleiman, D. & Awajan, A. (2020). Deep Learning Based Abstractive Text Summarization:
Approaches, Datasets, Evaluation Measures, and Challenges. Mathematical
Problems in Engineering, 2020.
Suter, J., Ebling, S. & Volk, M. (2016). Rule-based Automatic Text Simplification for
German.
Swayamdipta, S. (2019, januari 22). Learning Challenges in Natural Language Processing.
Verkregen 1 april 2022, van https : / / www . microsoft . com / en - us /
research/video/learning-challenges-in-natural-language-processing/
Tanya Goyal, G. D., Junyi Jessy Li. (2022). News Summarization and Evaluation in the
Era of GPT-3. arXiv preprint.
Thangarajah, V. (2019). Python current trend applications-an overview.
Tops, W., Callens, M., Brysbaert, M. & Schouten, E. L. (2018). Slagen met Dyslexie in
Het Hoger Onderwijs. Owl Press.
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B.,
Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E. & Lample, G.
(2023). LLaMA: Open and Efficient Foundation Language Models.
Van Brakel, R. (2022). De controle op het gebruik van algoritmische surveillanceonder
druk? Een exploratie door de lens van de relationele ethiek. Tijdschrift
voor Mensenrechten, 2022(1), 23–28.
van der Meer, C. (2022). Dyslexie hebben is Niet Zo Raar: Lezen is iets heel onnatuurlijks.
https://www.demorgen.be/beter- leven/dyslexie- hebben- is- niet- zoraar-
lezen-is-iets-heel-onnatuurlijks~bc608101/
Vasista, K. (2022). Evolution of AI Design Models. Central Asian Journal of Theoretical
and Applied Science, 3(3), 1–4.
Verhoeven, W. (2023, februari 8). Applaus voor de studenten die ChatGPT gebruiken
(Trends, Red.). https://trends.knack.be/economie/bedrijven/applausvoor-
de-studenten-die-chatgpt-gebruiken/article-opinion-1934277.html?
cookie_check=1676034368
Verma, P. & Verma, A. (2020). A review on text summarization techniques. Journal
of scientific research, 64(1), 251–257.
White, J., Fu, Q., Hays, S., Sandborn, M., Olea, C., Gilbert, H., Elnashar, A., Spencer-
Smith, J. & Schmidt, D. C. (2023). A Prompt Pattern Catalog to Enhance Prompt
Engineering with ChatGPT.
Xu, W., Callison-Burch, C. & Napoles, C. (2015). Problems in current text simplification
research: New data can help. Transactions of the Association for Computational
Linguistics, 3, 283–297.
Zeng, Q., Kim, E., Crowell, J. & Tse, T. (2005). A Text Corpora-Based Estimation of
the Familiarity of Health Terminology. In J. L. ”Oliveira, V. Maojo, F. Martín-
Sánchez & A. S. Pereira (Red.), Biological and Medical Data Analysis (pp. 184–
192). Springer Berlin Heidelberg.
Zhang, M., Riecke, L. & Bonte, M. (2021). Neurophysiological tracking of speech-structure
learning in typical and dyslexic readers. Neuropsychologia, 158, 107889.
Zhou, W., Ge, T., Xu, K., Wei, F. & Zhou, M. (2019). BERT-based Lexical Substitution. Proceedings
of the 57th Annual Meeting of the Association for Computational
Linguistics, 3368–3373. https://doi.org/10.18653/v1/P19-1328








