
Leveraging Social Media Data for Real-time COVID-19 Prediction in Belgium
Introduction: The outbreak of the 2019 coronavirus (COVID-19) is one of the worst recorded in history. According to the Institute for Health Metrics and Evaluation (IHME) at the University of Washington, the true global death toll is more than double the reported figures. Countless people who die while contaminated with SARS-CoV-2 are never tested for it, so their counts are not included in the official totals. Therefore, it is nearly impossible to investigate all the symptoms of the infection by relying only on health records. To better understand the full spectrum of the prevalence of COVID-19 and the symptoms experienced by infected people and make further inferences regarding the spread of the infection among people, there is a need to look beyond hospital- or clinic-focused studies. Researchers have begun to explore the use of digital trace data, particularly data from social media platforms, as a means to predict the virus's spread in various communities. It is a particularly innovative approach, using publicly available social media data to track the spread of the disease in real time.
Problem Statement: Social media data has a potential application in the early identification of novel virus symptoms in digital epidemiology. It is a critical competency that public health organizations are investing in in order to receive real-time signals of pandemic upticks and spread. However, social media data is often unorganized and a non-representative sample of the population due to the demographic skew in usage frequencies and access rates. As such, any direct estimate from a platform like Twitter is likely biased toward certain demographics. With this in mind, an attempt is made to use tweets (digital trace data) to make inferences about the granular level prevalence of COVID-19 infections in Belgium. The goal of this study is to determine how this digital trace data, which is unstructured, non-representative, and biased, might be used to make inferences about the granular level prevalence of COVID-19 infections in Belgium.

Research Questions: Several key research questions guide this study:
• How is the mass-scaled digital trace data (tweets) collected?
• How is the unstructured digital trace data transformed into structured survey-like objects amenable to statistical analysis?
• How can these biased survey-like objects be utilized for generating representative real-time estimates of COVID-19 cases at the municipality level in Belgium?
Hypothesis: The area-level prevalence of the COVID-19 pandemic (in Belgium) at its granular level (municipalities) can be modeled by Multilevel Regression and Post-Stratification (MrP) on features extracted (like age and gender) from aggregated tweets of users from different municipalities of Belgium to make real-time predictions and generate representative estimates. The results of Multilevel Regression and Post-Stratification (MrP) are similar to actual data on the prevalence of COVID-19 infections in Belgium.
Methodology:
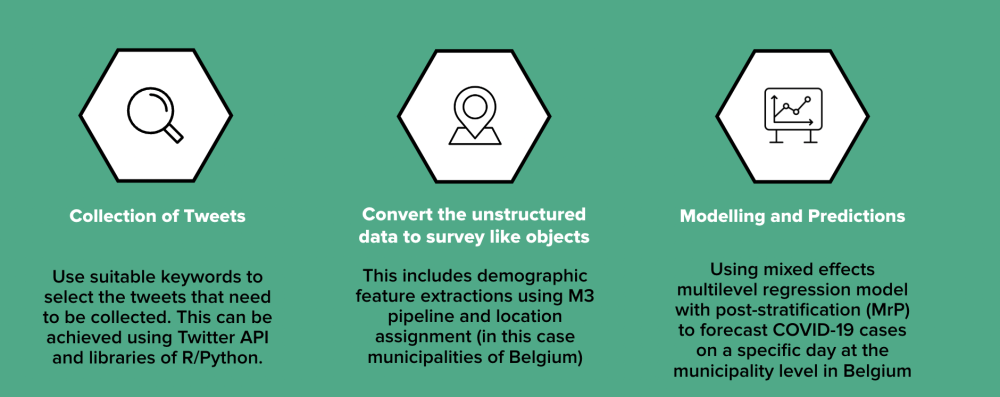
In this study, the following contributions are made to three core elements: collecting mass-scaled tweets, extracting demographic features and assigning a location value to convert unstructured digital data to survey-like objects, and using a multi-level regression model with post-stratification to make real-time predictions on the population using digital trace data.
The methodology comprises three main components:
- Data Collection:
- Tweets related to COVID-19 symptoms are collected from Twitter using specific keywords for a specific time range.
- Data Transformation:
- Demographic features such as age and gender are extracted from tweets using a deep learning model.
- Geolocation data for Belgian municipalities is obtained using sophisticated programming packages made available by Statbel.
- Statistical Analysis:
- A Multilevel Regression and Post-Stratification (MrP) model is employed to estimate COVID-19 prevalence based on demographic characteristics.
- Bayesian approaches using Stan and the 'rstan' package are used for modeling.
Results: A complete pipeline that includes the collection of social media data, converting it into organized survey-like objects, and finally fitting a mixed effects multi-level regression model with post-stratification (MrP) to forecast COVID-19 cases has been successfully built from scratch. The expectation from the model is not to make accurate predictions but to show that there is at least some correlation between the model estimates and the actual observed number of cases per municipality. Through that, the feasibility of the approach used in the study is established. The Pearson’s Correlation coefficient between the predictions based on the case count of January 23, 2022, from the model for the next day and the actual number of cases reported on January 24, 2022, is 0.938. This strong positive correlation is a very promising indication that there is an enormous signal in the Twitter data.
Discussions: This approach offers several advantages over traditional surveillance methods, including cost-effectiveness, real-time tracking, and user privacy protection. With no additional infrastructure requirements beyond a laptop and common software like R, Python, and Stan, it enables real-time tracking of the spread of diseases with data sourced from anonymous self-reported information online, eliminating the need for physical surveys. After processing, the data becomes completely anonymous, which protects user privacy. These advantages make social media monitoring an attractive research field for tracking epidemics, evaluating public health interventions, identifying high-risk areas, and identifying people who may require medical attention. Despite sampling bias and data limitations, it underscores the potential of social media monitoring in epidemiology and public health intervention. This has promising implications for real-time disease monitoring and control.
To the best of my knowledge, this is the first study in Belgium that focuses on extracting COVID-19 symptoms from public social media at the granular level of its municipalities to make inferences about the municipality-level spread of COVID-19 infections. Furthermore, not much work has been done with Belgian data using MrP. This study hopes to bridge that gap and encourage other scholars to pursue similar groundbreaking research.
Conclusion: A multitude of studies have been done as part of the reaction to this pandemic in an effort to improve our understanding and prevent the virus’s spread. The use of social media data to predict COVID-19 prevalence represents a novel strategy with valuable implications for public health authorities and the scientific community. In conclusion, it is suggested that this POC represents a very valuable source of information for the scientific community and public health authorities. This approach has the potential to make a significant contribution to the fight against any infectious disease, such as COVID-19, by accelerating the rate at which new cases are detected, using sources other than official data, and carrying out informed, targeted interventions to mitigate the spread of the disease.







