
Sociale Media: Making Populism Great Again?
“Today in the United States the top 1% earns more income than the bottom 50%. Does that make sense?”
“The Middle-Class has become the new poor in this country and our incompetent politicians are unable to do anything about it. They don’t care!”
Deze twee berichten werden gedeeld op Facebook door twee Amerikaanse politici tijdens de vorige presidentsverkiezingen. De eerste komt van Bernie Sanders, dat verbaast je misschien niet. De tweede werd geschreven door Donald Trump. Lijkt vreemd toch? Twee politici die qua standpunten en politiek bijna niet verder uit elkaar kunnen liggen, zeggen hier ongeveer hetzelfde in andere woorden. Niet zo vreemd wanneer je weet dat ze wel iets delen: een populistische politieke stijl.
Trump en Sanders zijn twee heel atypische kandidaten binnen hun eigen partij die het toch, best onverwachts, heel ver gebracht hebben, onder andere dankzij een erg succesvolle sociale mediastrategie. Trumps getwitter was dagelijks nieuws, en discussies hierover en over populisme waren (en zijn) dagelijkse kost. Iedereen lijkt er een mening over te hebben, al is deze mening niet altijd even gefundeerd. Daarom onderzocht communicatiewetenschapster Jana Goyvaerts (VUB) hoe populisme tot uiting komt en misschien zelfs versterkt wordt via sociale media. Ze keek naar de Facebook-, Instagram- en Twitterprofielen van Donald Trump en Bernie Sanders om de overeenkomsten in de praktijk te testen.
Wat is populisme, en waarom past het zo goed bij sociale media?
Goyvaerts kijkt in haar onderzoek niet naar populisme als een ideologie, maar als een politieke stijl, een manier om aan politiek te doen. Op die manier kan je een erg rechtse en erg linkse politicus op eenzelfde manier te bekijken. Hun ideologie verschilt enorm, maar de manier waarop ze aan politiek doen is gelijkaardig. Dat komt tot uiting via specifieke kenmerken van populisme, die in de thesisstudie vergeleken werden met verschillende kenmerken van sociale media.
Populisten formuleren alles als een tegenstelling tussen de machtige elite en het volk, dat de echte macht verdient. Zij claimen ‘het volk’ te vertegenwoordigen en willen hen de macht teruggeven. Dit gaat makkelijk op sociale media: je kan er rechtstreeks communiceren met mensen, of toch die illusie wekken, en meer mensen bereiken dan wanneer je een hele namiddag handjes schudt op de markt. Trump retweet bijvoorbeeld gigantisch veel van gewone burgers en creëert zo het gevoel dat hij voor hen spreekt. Maar Trump en Sanders delen bijvoorbeeld ook vaak foto’s van grote massa’s mensen bij hun bijeenkomsten, zodat het lijkt alsof het hele volk achter hen staat.
Om hun band met het volk te benadrukken, gedragen populistische politici zich vaak ongebruikelijk of anders dan traditionele politici. In hun actief gebruik van sociale media, bijvoorbeeld door sprekende foto’s op Instagram te delen en bepaalde Hashtags te gebruiken, gedragen populistische politici zich al anders dan traditionele politici. Tijdens de republikeinse debatten tweette Bernie Sanders bijvoorbeeld de hele tijd zijn mening live met #DebateWithBernie. En Donald Trump gedraagt zich natuurlijk helemaal ongebruikelijk: door korte en harde taal te gebruiken, distantieert hij zich enorm van traditionele, elitaire politici en geeft hij veel Amerikanen het gevoel dat hij het ‘zegt zoals het is’.
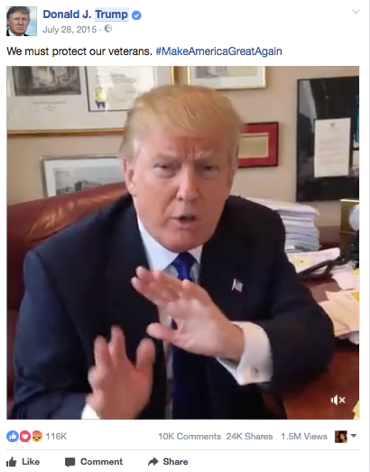
Vaak ligt bij populisme ook de nadruk op één sterke leider die het volk gaat redden. Sociale media zijn op zich erg persoonlijk, waardoor ze makkelijk te gebruiken zijn in populistische communicatie. Om dit te benadrukken, delen Trump en Sanders soms video’s van zichzelf waar ze hun mening geven over een thema. Trump doet dit vaak heel kort, hier zie je een screenshot van een filmpje waarin hij zegt “One of the most important things that we’ve been talking about lately is protecting our veterans; we must protect and cherish and take care of our veterans.”
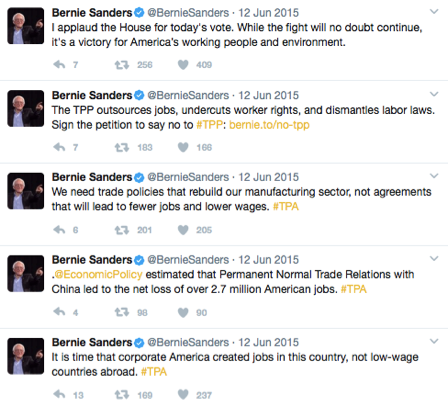
Dit kort taalgebruik is ten slotte ook heel kenmerkend voor populisme. Ze maken van een vaak ingewikkelde situatie, zoals handelsverdragen of immigratie, een makkelijk uit te leggen crisis waar het volk de dupe van is. Dit kan goed op sociale media zoals Twitter, waar je maar een beperkt aantal tekens hebt. Een voorbeeld hiervan zijn deze tweets van Bernie Sanders, over de TPP/TPA-akkoorden. Eigenlijk een moeilijke situatie, waar zowel voor- als nadelen aan verbonden zijn, maar hij reduceert dit in een paar tweets.
Wat betekent dit dan?
Op verschillende manieren bewees Goyvaerts dat populisme en sociale media erg goed samengaan, zowel in theorie als in de praktijk. Trump en Sanders gebruikten sociale media op een heel slimme manier om hun boodschap op een populistische manier te verspreiden. Ze waren allebei een kleine kandidaat binnen een grote partij, die door bijna niemand serieus genomen werd. Toch groeide Sanders uit tot een symbool van een beweging en de belangrijkste tegenkandidaat van Hillary Clinton, en Donald Trump schopte het zelfs tot president. Er valt over te discussiëren of dit positief is, maar alleszins bewijzen deze resultaten dat alle politici sociale media én populisme serieus genoeg moeten nemen.
Bibliografie
Aalberg, T., & de Vreese, C. H. (2017). Introduction. Comprehending Populist Political Communication. In Populist Political Communication in Europe (pp. 3–11). New York, Abingdon: Routledge.
Alvares, C., & Dahlgren, P. (2016). Populism, extremism and media: Mapping an uncertain terrain. European Journal of Communication, 31(1), 46–57.
AP. (2015, oktober 27). Head of Podemos party, Pablo Iglesias shakes up Spain politics. The Economic Times. Geraadpleegd van http://economictimes.indiatimes.com/news/international/world-news/head-…
Bartlett, J. (2014). Populism, social media and democratic strain. Democracy in Britain: Essays in honour of James Cornford, 91–96.
Bartlett, J., Birdwell, J., & Littler, M. (2011). The new face of digital populism. London: Demos.
Baxter, P., & Jack, S. (2008). Qualitative Case Study Methodology: Study Design and Implementation for Novice Researchers. The Qualitative Report, 13(4), 544–559.
Bimber, B. (1998). The Internet and political transformation: Populism, community, and accelerated pluralism. Polity, 31(1), 133–160.
Bimber, B. (2014). Digital Media in the Obama Campaigns of 2008 and 2012: Adaptation to the Personalized Political Communication Environment. Journal of Information Technology & Politics, 11(2), 130–150.
Block, E., & Negrine, R. (2017). The Populist Communication Style: Toward a Critical Framework. International Journal of Communication, 11(0), 20.
Blumer, H. (1954). What is Wrong with Social Theory? American Sociological Review, 19(1), 3–10.
Blumler, J. G., & Kavanagh, D. (1999). The third age of political communication: Influences and features. Political Communication, 16(3), 209–230.
Chadwick, A., Dennis, J., & Smith, A. P. (2016). Politics in the Age of Hybrid Media: Power, Systems, and Media Logics. In The Routledge Companion to Social Media and Politics (p. 538). New York, Abingdon: Routledge.
Creech, B. (2014). Disciplines of truth: The ’Arab Spring’, American journalistic practice, and the production of public knowledge. Journalism, 1–17.
Dang-Xuan, L., Stieglitz, S., Wladarsch, J., & Neuberger, C. (2013). An investigation of influentials and the role of sentiment in political communication on twitter during election periods. Information, Communication & Society, 16(5), 795–825.
De Cleen, B., & Carpentier, N. (2010). Contesting the populist claim on “the people” through popular culture: the 0110 concerts versus the Vlaams Belang. Social Semiotics, 20(2), 175–196.
De Vos, P. (2005). Het uur van de rattenvangers: de populistische verleiding en hoe ze te weerstaan. Oikos, 35, 37–45.
Deller, R., & Hallam, S. (2011). Twittering on: Audience research and participation using Twitter. Participations Journal of Audience & Reception Studies, 8(1), 216–245.
Dyrberg, T. B. (2003). Right/left in the context of new political frontiers. Journal of Language & Politics, 2(2), 333–360.
Engesser, S., Ernst, N., Esser, F., & Büchel, F. (2016). Populism and social media: how politicians spread a fragmented ideology. Information, Communication & Society, 0(0), 1–18.
Enli, G. (2016). “Trust Me, I Am Authentic!”: Authenticity Illusions in Social Media Politics. In The Routledge Companion to Social Media and Politics (pp. 121–136). New York, Abingdon: Routledge.
Enli, G. (2017). Twitter as arena for the authentic outsider: exploring the social media campaigns of Trump and Clinton in the 2016 US presidential election. European Journal of Communication, 32(1), 50–61.
Enli, G., & Moe, H. (2013). Introduction to Special Issue. Information, Communication & Society, 16(5), 637–645.
Enli, G., & Naper, A. A. (2016). Social Media Incumbent Advantage: Barack Obama’s and Mitt Romney’s Tweets in the 2012 U.S. Presidential Election Campaign. In The Routledge Companion to Social Media and Politics (pp. 364–377). New York, Abingdon: Routledge.
Enli, G. S., & Skogerbø, E. (2013). Personalized Campaigns in Party-Centred Politics. Information, Communication & Society, 16(5), 757–774.
Frizell, S. (2015, juli 29). Bernie Sanders Hosts Biggest Organizing Event of 2016 So Far. Geraadpleegd 20 mei 2017, van http://time.com/3976557/bernie-sanders-house-party/
Galston, W. A., & Hendrickson, C. (2017, april 28). Why are populists winning online? Social media reinforces their anti-establishment message | Brookings Institution. Geraadpleegd 25 mei 2017, van https://www.brookings.edu/blog/techtank/2017/04/28/why-are-populists-wi…
Gerbaudo, P. (2015). Populism 2.0 : Social media activism, the generic Internet user and interactive direct democracy. In Social Media, politics and the state: protests, revolutions, riots, crime and policing in the age of Facebook, Twitter and Youtube (pp. 67–87). New York, Abingdon: Routledge.
Gottfried, J., & Shearer, E. (2016). News Use Across Social Media Platforms 2016. Pew Research Center’s Journalism Project. Geraadpleegd van http://www.journalism.org/2016/05/26/news-use-across-social-media-platf…
Greenwood, S., Perrin, rew, & Duggan, M. (2016). Social Media Update 2016. Pew Research Center: Internet, Science & Tech. Geraadpleegd van http://www.pewinternet.org/2016/11/11/social-media-update-2016/
Haleva-Amir, S., & Nahon, K. (2016). Electoral Politics on Social Media: The Israeli Case. In The Routledge Companion to Social Media and Politics (pp. 471–487). New York, Abingdon: Routledge.
Highfield, T., & Bruns, A. (2016). Compulsory Voting, Encouraged Tweeting? Australian Elections and Social Media. In The Routledge Companion to Social Media and Politics (pp. 338–350). New York, Abingdon: Routledge.
Jagers, J., & Walgrave, S. (2007). Populism as political communication style: An empirical study of political parties’ discourse in Belgium. European Journal of Political Research, 46(3), 319–345.
Jensen, J. L., Ørmen, J., & Lomborg, S. (2016). The Use of Twitter in the Danish EP Elections 2014. In The Routledge Companion to Social Media and Politics (pp. 503–517). New York, Abingdon: Routledge.
Katsambekis, G. (2014). The Place Of The People In Post-Democracy: Researching “Antipopulism” And Post-Democracy In Crisis-Ridden Greece. Postdata, 19(2), 555–582.
Kim, Y. (2008). Digital populism in South Korea? Internet culture and the trouble with direct participation. Korea Economic Institute Academic Paper Series, 3(8), 1–8.
Klinger, U. (2013). Mastering the Art of Social Media. Swiss parties, the 2011 national election and digital challenges. Information, Communication & Society, 16(5), 717–736.
Krämer, B. (2014). Media Populism: A Conceptual Clarification and Some Theses on its Effects. Communication Theory, 24(1), 42–60.
Larsson, A. O., & Moe, H. (2016). From Emerging to Established? A Comparison of Twitter Use during Swedish Election Campaigns in 2010 and 2014. In The Routledge Companion to Social Media and Politics (pp. 311–324). New York, Abingdon: Routledge.
Lilleker, D. G., Jackson, N., & Koc-Michalska, K. (2016). Social Media in the UK Election Campaigns 2008-2014: Experimentation, Innovation and Convergence. In The Routledge Companion to Social Media and Politics (pp. 325–337). New York, Abingdon: Routledge.
Moffitt, B. (2016). The Global Rise of Populism: Performance, Political Style, and Representation. Stanford: Stanford University Press.
Mortelmans, D. (2013). Handboek Kwalitatieve Onderzoeksmethoden (Vierde herziene druk). Leuven: Acco.
Mudde, C. (2004). The Populist Zeitgeist. Government and Opposition, 39(4), 541–563.
Nahon, K. (2016). Where there is social media there is politics. In Routledge companion to social media and politics (pp. 39–55). New York: Routledge.
Newman, N., Fletcher, R., Kalogeropoulos, A., Levy, D. A. L., & Nielsen, R. K. (2017). Reuters Institute Digital News Report 2017 (p. 133). Reuters Institute for the Study of Journalism. Geraadpleegd van https://reutersinstitute.politics.ox.ac.uk/sites/default/files/Digital%…
Nuernbergk, C., Wladarsch, J., Neubarth, J., & Neuberger, C. (2016). Social Media Use in the German Election Campaign 2013. In The Routledge Companion to Social Media and Politics (pp. 419–433). New York, Abingdon: Routledge.
Papa, F., & Francony, J.-M. (2016). The 2012 French Presidential Campaign: First Steps into the Political Twittersphere. In The Routledge Companion to Social Media and Politics (pp. 378–390). New York, Abingdon: Routledge.
Pappas, T. S., & Aslanidis, P. (2015). Greek populism: A political drama in five acts. European Populism in the Shadow of the Great Recession, 181–196.
Recuero, R., Zago, G., & Bastos, M. T. (2016). Twitter in Political Campaigns: The Brazilian 2014 Presidential Election. In The Routledge Companion to Social Media and Politics (pp. 518–530). New York, Abingdon: Routledge.
Reinemann, C., Aalberg, T., Esser, F., Strömbäck, J., & de Vreese, C. H. (2017). Populist Political Communication. Toward a Model of Its Causes, Forms, and Effects. In Populist Political Communication in Europe (pp. 12–24). New York, Abingdon: Routledge.
Rooduijn, M., & Pauwels, T. (2011). Measuring Populism: Comparing Two Methods of Content Analysis. West European Politics, 34(6), 1272–1283.
Rossi, L., & Orefice, M. (2016). Comparing Facebook and Twitter During the 2013 General Election in Italy. In The Routledge Companion to Social Media and Politics (pp. 434–446). New York, Abingdon: Routledge.
Simons, J. (2011). Mediated Construction of the People: Laclau’s Political Theory and Media Politics. In L. Dahlberg & S. Phelan (Red.), Discourse Theory and Critical Media Politics (pp. 201–221). Palgrave Macmillan UK.
Skovsgaard, M., & van Dalen, A. (2016). Not Just a Face(book) in the Crowd: Candidates’ Use of Facebook during the Danish 2011 Parliamentary Election Campaign. In The Routledge Companion to Social Media and Politics (pp. 351–363). New York, Abingdon: Routledge.
Splichal, S., & Dahlgren, P. (2016). Journalism between de-professionalisation and democratisation. European Journal of Communication, 31(1), 5–18.
Strauss, A., & Corbin, J. M. (1998). Basics of Qualitative Research: Techniques and Procedures for Developing Grounded Theory (Second edition). Newbury Park: Sage.
Strömbäck, J. (2008). Four phases of Mediatization: An Analysis of the Mediatization of Politics. Press/Politics, 13(3), 228–246.
Van Reybrouck, D. (2008, augustus 26). Pleidooi voor populisme. De Morgen. Geraadpleegd van http://www.demorgen.be/binnenland/pleidooi-voor-populisme-bfa383ee/
Van Reybrouck, D. (2011). Pleidooi voor populisme. Uitgeverij De Bezige Bij.
Vergeer, M. (2013). Politics, elections and online campaigning: Past, present . . . and a peek into the future. New Media & Society, 15(1), 9–17.
Willnat, L., & Min, Y. (2016). The Emergence of Social Media Politics in South Korea: The Case of the 2012 Presidential Election. In The Routledge Companion to Social Media and Politics (pp. 391–405). New York, Abingdon: Routledge.
Wright, S., Graham, T., & Jackson, D. (2016). Third Space, Social Media, and Everyday Political Talk. In The Routledge Companion to Social Media and Politics (pp. 74–88). New York, Abingdon: Routledge.








