
Hoe Netflix weet welke film jij en je vriendengroep samen willen zien
1. Inleiding
Zoals vele andere websites maakt Netflix gebruik van recommender systemen. De taak van zo'n systeem is niets minder dan het aanraden van producten en diensten aan zijn gebruikers. Tot op heden werden vooral individuele mensen beschouwd. Het wordt natuurlijk een heel pak complexer wanneer je met een groep te maken hebt. Het aanbevelingssysteem weet misschien wel wat de individuele voorkeuren zijn van deze mensen, maar niet in welke mate ze bereid zijn om toe te geven aan de voorkeuren van de andere groepsleden. Zo kan het bijvoorbeeld zijn dat je een sterke voorkeur hebt voor horrorfilms, terwijl je vrienden veel liever comedies kijken. Welke film gaan jullie dan zien en hoe moet het systeem dit te weten komen?
2. Recommender systemen
Hoe werkt een traditioneel recommender systeem nu juist? Er bestaan drie basismethodes:
- Content-based filtering: Bij deze aanpak gaat de recommender producten aanraden die gelijkaardig zijn aan de producten die de gebruiker al geconsumeerd heeft. Als Netflix bijvoorbeeld merkt dat je naar veel horrorfilms kijkt, dan zal deze ook horrorfilms aanraden.
- Collaborative filtering: De veronderstelling is hier dat mensen met dezelfde smaak, ook dezelfde producten goed vinden. Stel nu dat de recommender merkt dat persoon A en persoon B een gelijkaardige smaak hebben. Als persoon A dan een film heeft gezien die persoon B nog niet heeft gezien, dan is het misschien nuttig om deze film ook aan persoon B aan te raden.
- Critiquing: Dit soort recommender zal consecutief producten blijven aanraden aan de gebruiker. De gebruiker moet deze producten dan een score geven of classificeren als goed of slecht. Gebaseerd op deze informatie zal het systeem dan leren wat jouw voorkeur juist is.
De gebruikte methode hangt af van de context en de beschikbare data over de gebruikers.
3. Uitbreiden naar een groep mensen
3.1 Huidige aanpak
Huidige recommender systemen maken gebruik van voting mechanismen. Elke gebruiker heeft zijn eigen recommender die weet wat de voorkeur is van zijn gebruiker. De recommenders gaan dan stemmen voor het beste product. Zo kunnen ze bijvoorbeeld merken dat vijf van de zes gebruikers graag een comedy film willen zien. In dat geval beslissen ze om de comedy aan te raden aan de groep.
3.2 Nieuwe aanpak
Wat nu als de vijf mensen in bovenstaand voorbeeld bereid zijn om toe te geven aan de voorkeur van de zesde persoon? Hoe kunnen de recommenders hierop voorzien zijn?
Eerst en vooral is het belangrijk om te beseffen dat de aan te raden producten zich bevinden in een hoogdimensionale ruimte. Dit klinkt ingewikkeld, maar dat is het zeker niet. Stel nu dat we een auto willen beschrijven. De eigenschappen of features zijn bijvoorbeeld de topsnelheid en de cilinderinhoud. Voor de Ford Focus RS is de topsnelheid 266 km/h en de cilinderinhoud 2522cc terwijl dit voor de Audi A4 respectievelijk 244 km/h en 1968cc is. Dit kunnnen we visualiseren in een 2-dimensionale ruimte zoals in onderstaade figuur.
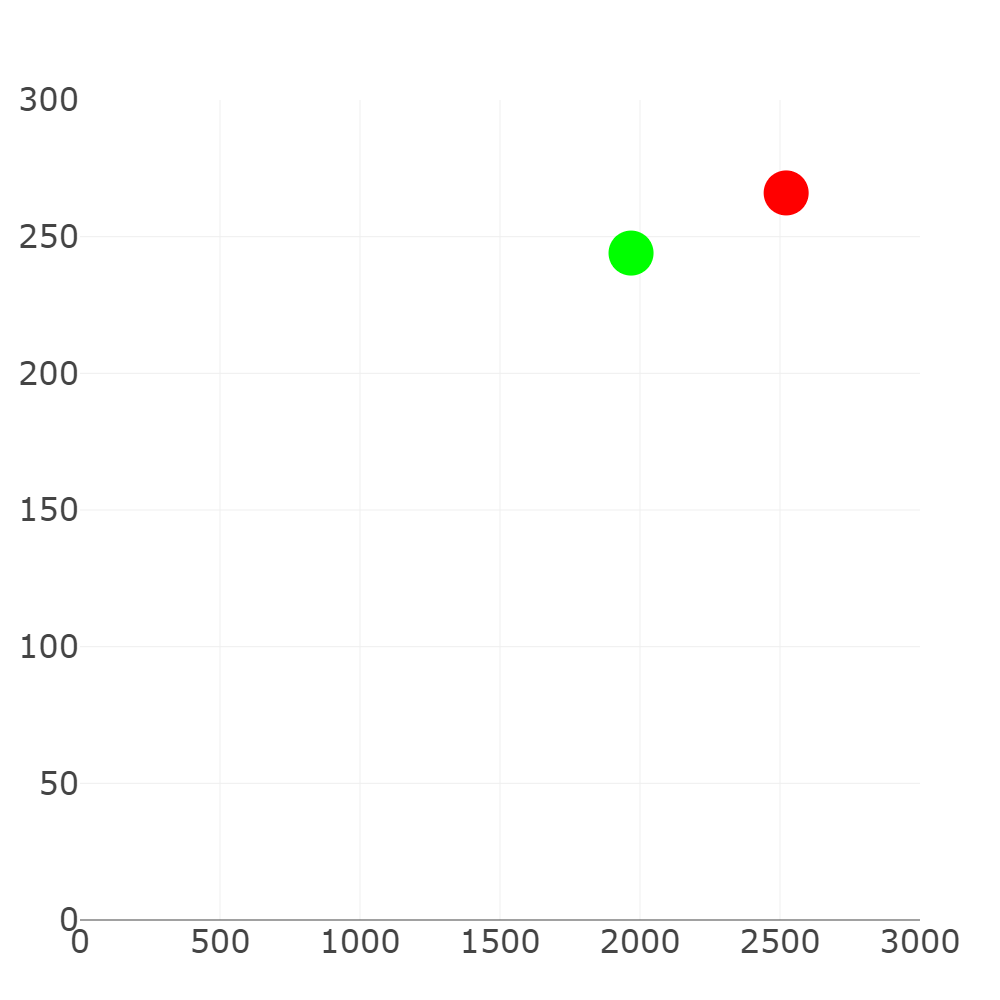
Nu is het zo dat een auto nog veel meer eigenschappen heeft, denk maar aan het gewicht, het vermogen, enz... Elke feature die je toevoegt zal een extra dimensie introduceren. Als we bijvoorbeeld het gewicht van de wagens mee willen tekenen in bovestaande figuur, dan zullen we een 3-D figuur moeten gebruiken. Vanaf de vierde dimensie wordt het moeilijk om het te visualiseren, maar het principe blijft hetzelfde: elk product is weer te geven door een punt in deze ruimte. Algemener spreekt men in de wereld van AI over objecten in plaats van producten. Om deze reden wordt deze hoogdimensionale ruimte ook de object space genoemd.
Wat kunnen we nu gaan doen met deze notie van een object space? Hier wordt eerst en vooral een belangrijke veronderstelling gemaakt: Objecten die dicht bij elkaar gelegen zijn in de object space, zijn gelijkaardig. Gegeven dat er genoeg informatieve features zijn, is dit een redelijke assumptie. Als je bijvoorbeeld bij een film enkel de speelduur zou gebruiken, dan houdt dit uiteraard geen steek. Uit deze veronderstelling weten we dus dat wanneer we voor elke gebruiker in de groep een voorbeeld hebben van een object dat hij of zij leuk vond (= positief object), dan zal hij of zij de omliggende objecten in de object space misschien ook leuk vinden. Stel nu dat we in de object space een hypersfeer (= hoogdimensionale cirkel) maken die net voor elke gebruiker minstens één positief object bevat. Dan is onder de gemaakte assumptie redelijk om te gokken dat het object dat iedereen leuk vindt ergens in deze hypersfeer ligt.
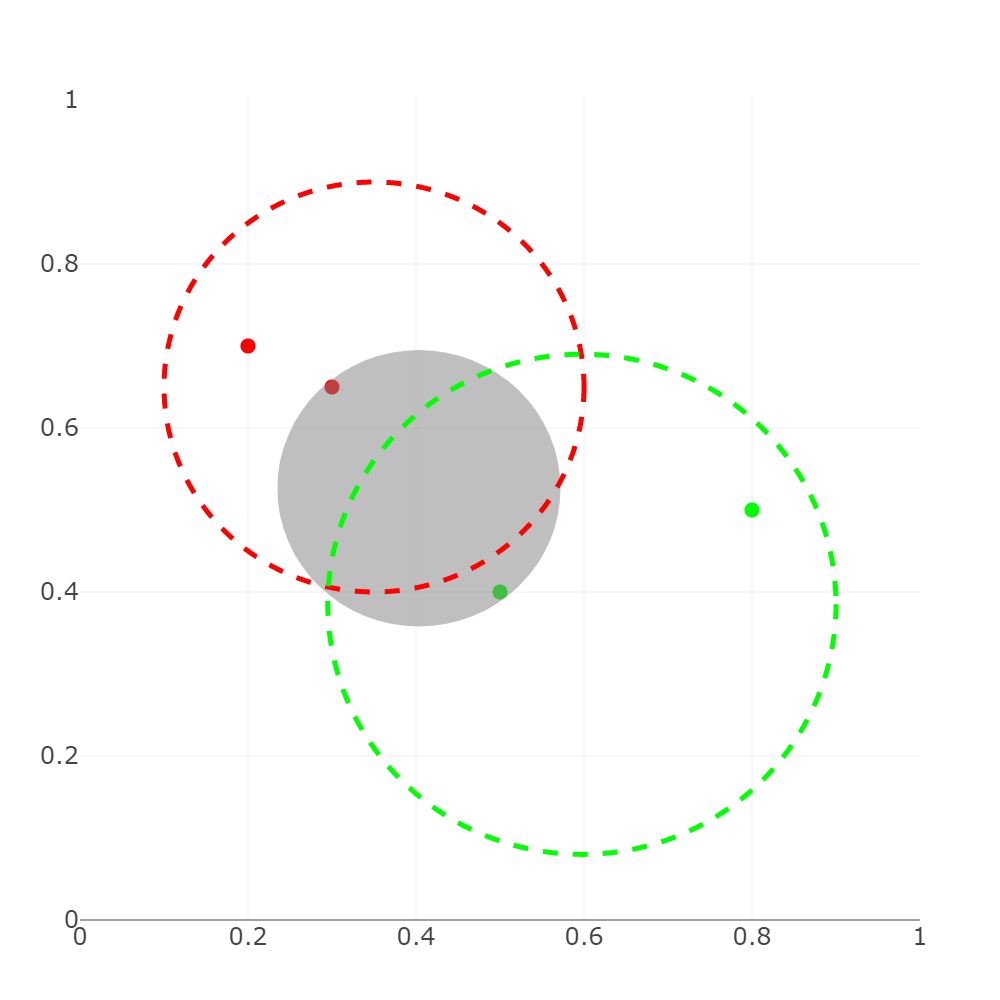
In bovenstaande figuur staat hiervan een concreet voorbeeld met twee gebruikers in een 2-D ruimte, elk met hun eigen kleur. De recommender heeft al voorbeelden van objecten die de twee gebruikers leuk vinden (de rode en groene stippen). De stippellijnen vormen het gebied van objecten die de twee gebruikers als positief evaren, maar deze zijn niet gekend door de computer. Het overlappende gebied tussen deze twee stippellijnen bevat dus objecten waarmee beide gebruikers tegelijkertijd tevreden zijn en de recommender moet dit gebied dus ook vinden. De grijze cirkel is niets minder dan de kleinst mogelijke cirkel die minstens één positief punt van elke gebruiker bevat (een rood en een groen punt dus). En inderdaad: de grijze cirkel bevat een groot deel van de regio waar de twee stippellijnen overlappen. Nu rest de computer enkel nog de taak om een willekeurig punt te kiezen in deze grijze cirkel om dan vervolgens te vragen aan de groepsleden of ze tevreden zijn met dat object. Merk op dat hierbij de cirkel de volgende keer waarschijnlijk zal krimpen indien een gebruiker aangeeft dat hij of zij tevreden is om uiteindelijk bij het optimale object uit te komen.
3.3 Is dit nu alles?
Absoluut niet, in deze scriptie zijn nog een aantal bijdragen, zoals bijvoorbeeld de detectie of mensen überhaupt tot een akkoord kunnen komen en het automatisch onderverdelen van mensen in kleinere groepen. De geïnteresseerde lezer wordt dan ook doorverwezen naar het volledige werk.
Bibliografie
[1] D. Angluin. Queries and concept learning. Machine Learning, 2(4):319–342, Apr 1988.
[2] D. Angluin. Queries revisited. In N. Abe, R. Khardon, and T. Zeugmann, editors, Algorithmic Learning Theory, pages 12–31, Berlin, Heidelberg, 2001. Springer Berlin Heidelberg.
[3] L. Ardissono, A. Goy, G. Petrone, M. Segnan, and P. Torasso. Intrigue: Personalized recommendation of tourist attractions for desktop and hand held devices. Applied Artificial Intelligence, 17(8-9):687–714, 2003.
[4] L. Boratto and S. Carta. State-of-the-Art in Group Recommendation and New Approaches for Automatic Identification of Groups, pages 1–20. Springer Berlin Heidelberg, Berlin, Heidelberg, 2011.
[5] T. De Pessemier, S. Dooms, and L. Martens. Comparison of group recommendation algorithms. Multimedia Tools and Applications, 72(3):2497–2541, Oct 2014.
[6] P. Dragone, S. Teso, and A. Passerini. Constructive preference elicitation over hybrid combinatorial spaces. CoRR, abs/1711.07875, 2017.
[7] P. Dragone, S. Teso, and A. Passerini. Constructive preference elicitation. Frontiers in Robotics and AI, 4, 01 2018.
[8] E. V. B. P. P. E. Abbasnejad, S. Sanner. Learning community-based preferences via dirichlet process mixtures of gaussian processes. In In Proceedings of the 23rd International Joint Conference on Artificial Intelligence (IJCAI), 2013.
[9] A. Felfernig, L. Boratto, M. Stettinger, and M. Tkalčič. Group Recommender Systems: An Introduction. SpringerBriefs in Electrical and Computer Engineering. Springer International Publishing, Cham, 2018.
[10] K. Fischer, B. Gärtner, and M. Kutz. Fast smallest-enclosing-ball computation in high dimensions. In G. Di Battista and U. Zwick, editors, Algorithms - ESA 2003, pages 630–641, Berlin, Heidelberg, 2003. Springer Berlin Heidelberg. 73 Bibliography
[11] I. Garcia, S. Pajares, L. Sebastia, and E. Onaindia. Preference elicitation techniques for group recommender systems. Information Sciences, 189:155 – 175, 2012.
[12] B. Gärtner and S. Schönherr. An efficient, exact, and generic quadratic programming solver for geometric optimization. In Proceedings of the sixteenth annual symposium on computational geometry, SCG ’00, pages 110–118. ACM, 2000.
[13] M. Grabisch, J.-L. Marichal, R. Mesiar, and E. Pap. Aggregation functions: Means. Information Sciences, 181(1):1–22, 2011.
[14] M. Kompan and M. Bielikova. Group recommendations: Survey and perspectives. COMPUTING AND INFORMATICS, 33(2), 2014.
[15] J. Leino and K. jouko Räihä". Case amazon: ratings and reviews as part of recommendations. In In RecSys ’07: Proceedings of the 2007 ACM conference on Recommender systems, pages 137–140. ACM, 2007.
[16] V. Melnikov and E. Hüllermeier. Learning to aggregate using uninorms. volume 9852, pages 756–771. Springer Verlag, 2016.
[17] M. O’Connor, D. Cosley, J. A. Konstan, and J. Riedl. Polylens: A recommender system for groups of users. In ECSCW’01: Proceedings of the seventh conference on European Conference on Computer Supported Cooperative Work, pages 199– 218, Norwell, MA, USA, 2001. Kluwer Academic Publishers.
[18] K. O’Hara, M. Lipson, M. Jansen, A. Unger, H. Jeffries, and P. Macer. Jukola: Democratic music choice in a public space. In Proceedings of the 5th Conference on Designing Interactive Systems: Processes, Practices, Methods, and Techniques, DIS ’04, pages 145–154, New York, NY, USA, 2004. ACM.
[19] G. Pigozzi, A. Tsoukiàs, and P. Viappiani. Preferences in artificial intelligence. Annals of Mathematics and Artificial Intelligence, 77(3):361–401, Aug 2016.
[20] F. Ricci, L. Rokach, B. Shapira, and P. B. Kantor. Recommender Systems Handbook. Springer-Verlag, Berlin, Heidelberg, 2011.
[21] B. Settles. Active learning. Synthesis Lectures on Artificial Intelligence and Machine Learning, 18:1–111, 2012.
[22] E. Welzl. Smallest enclosing disks (balls and ellipsoids). In H. Maurer, editor, New Results and New Trends in Computer Science, pages 359–370, Berlin, Heidelberg, 1991. Springer Berlin Heidelberg.
[23] Z. Yu, X. Zhou, Y. Hao, and J. Gu. Tv program recommendation for multiple viewers based on user profile merging. User Modeling and User-Adapted Interaction, 16(1):63–82, Mar 2006.










