
STATISTIEK ALS GLAZEN BOL: Wat is de kans op een miskraam?
Niets is zo speciaal als het ontstaan van nieuw leven. Vorig jaar werden er in België ongeveer 65.000 kinderen geboren. Jammer genoeg eindigt tot 30% van de zwangerschappen in een miskraam. Dit wil zeggen dat er in 2018 naar schatting 28.000 baby’s niet geboren werden. Een getal dat vergelijkbaar is met het aantal inwoners van twee uit de kluiten gewassen Vlaamse dorpen!
Om zwangerschappen goed te kunnen opvolgen, trachten onderzoekers modellen op te stellen die het risico op een miskraam voorspellen aan de hand van bepaalde eigenschappen van de ouders. Ook met dit doel voor ogen schreef Helene Vermeulen haar thesis. Hiervoor gebruikte ze een relatief nieuwe statistische techniek, genaamd ‘joint latent class modelling’, waarmee ze, net als met een glazen bol, in de toekomst probeert te kijken. De techniek kan namelijk het risico op een miskraam voorspellen op elk moment van de zwangerschap en brengt bovendien de groei van de foetus in kaart. Hoewel deze thesis focust op het voorspellen van miskramen, kan deze methode in de medische wereld nog veel meer toepassingsgebieden vinden.
‘Joint latent class modelling’ voor dummies
De groei van de foetus kan een fundamentele invloed hebben op het al dan niet optreden van een miskraam. Het is daarom belangrijk om de groei van de foetus en het risico op een miskraam samen te modelleren. Dit verklaart het woord ‘joint’ in ‘joint latent class modelling’. Daarnaast eindigen lang niet alle zwangerschappen in een miskraam. Er zijn dus twee klassen van zwangerschappen, deze met een positieve en deze met een negatieve uitkomst. Aangezien men tijdens de zwangerschap de uitkomst nog niet kent, zijn deze klassen latent ofwel - niet waarneembaar. Dit verklaart de term ‘latent class’ in 'joint latent class modelling'.
Een variëteit aan modellen
Er werd een variëteit aan modellen opgesteld op basis van 753 zwangerschappen met gekende uitkomst. De dataset afkomstig van deze zwangerschappen bevatte eveneens informatie over eigenschappen van de moeder zoals bijv. de leeftijd, het BMI, het aantal eerdere miskramen, enz. Bovendien bevatte de dataset ook informatie over het verloop van de zwangerschap. Voorbeelden hiervan zijn de hoeveelheid pijn die de moeder ervaarde, de mate van misselijkheid, gegevens van de echografie, enz. Al deze gegevens werden geïntegreerd in een aantal modellen die de kans op een miskraam kunnen voorspellen en de groei van de foetus in kaart kunnen brengen.
 Illustratie van een echografie genomen tijdens de zwangerschap - CC Wikimedia
Illustratie van een echografie genomen tijdens de zwangerschap - CC Wikimedia
Opmerkelijk was dat het model met twee latente klassen (miskraam/geen miskraam) een slechte voorspelling gaf voor de werkelijke uitkomst van de zwangerschap. Dit model werd daarom verder uitgebreid naar een verzameling modellen met meerdere latente klassen. Van deze verzameling modellen, geeft het model met 5 latente klassen de beste voorspellingen. In onderstaande figuur is te zien dat de vrouwen waarvoor het model voorspelt dat er een miskraam zal optreden in de eerste en de derde klasse terecht komen. Vrouwen waarvoor de kans op een miskraam uiterst klein is, worden door het model in de tweede, vierde of vijfde klasse ingedeeld. Het probleem met dit model ligt echter in de interpretatie. Waarom werkt het model beter met 5 klassen in plaats van 2? Bestaan er dan nog groepen buiten de twee groepen waar vrouwen ofwel een miskraam krijgen ofwel geen miskraam krijgen?
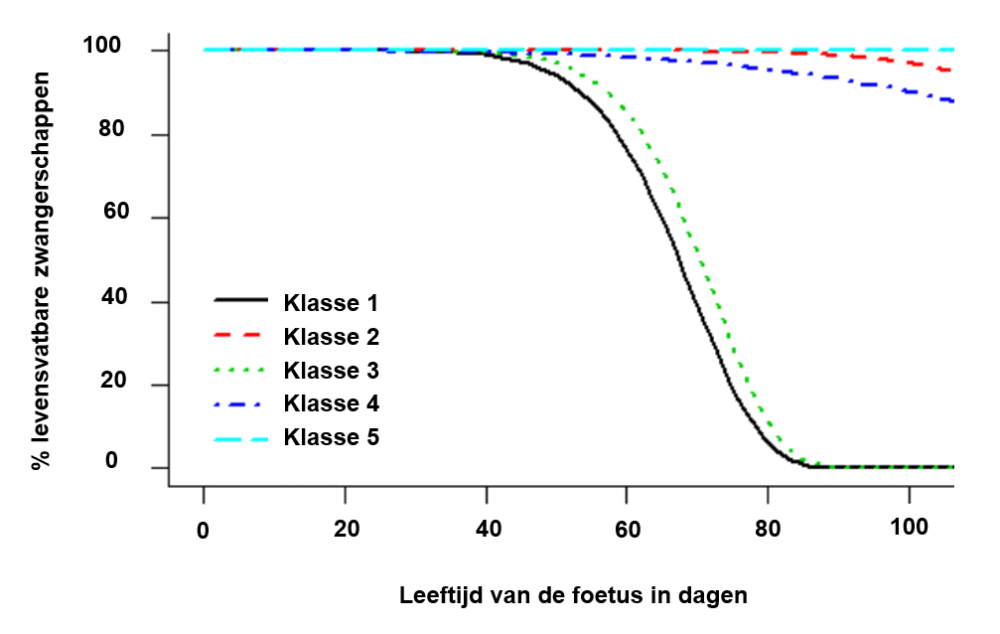
Illustratie van het risico op een miskraam in de vijf latente klassen.
Het zijn de verschillen in de eigenschappen van de ouders die ons op deze vraag een antwoord lijken te geven. De twee groepen (miskraam/geen miskraam) kunnen namelijk verder opgedeeld worden in 5 klassen op basis van de eigenschappen van de ouders. Zo zien we bijvoorbeeld dat, in de klassen waarvoor het model een miskraam voorspelt, de vrouwen in de derde klasse ouder zijn dan de vrouwen in de eerste klasse. Daarnaast kan de hartslag van de foetus vaker gedetecteerd worden in de derde klasse dan in de eerste klasse. Dit doet vermoeden dat de oorzaak van een miskraam in beide klassen anders is. Een hogere leeftijd van de moeder en de afwezigheid van een foetale hartslag verhogen dus de kans op een miskraam. Ook in de drie groepen waarvoor het model voorspelt dat de kans op een miskraam erg klein is, zijn de eigenschappen van de vrouwen verschillend. Door niet alleen de uitkomst van de zwangerschap maar ook de eigenschappen van de ouders in rekening te brengen, kan het model met 5 klassen een betere voorspelling geven voor toekomstige zwangerschappen dan het model met 2 klassen. Over het algemeen blijkt ook dat een hogere leeftijd van de vader de kans op een miskraam verhoogt en dat misselijkheid tijdens de zwangerschap de kans op een miskraam verlaagt.
Conclusie
Aan de hand van een ‘joint latent class model’ is het dus mogelijk de groei van de foetus op te volgen en tegelijkertijd een persoonlijke voorspelling te doen over de kans op een miskraam, en dit op elk moment van de zwangerschap. Hoewel de statistische techniek ‘joint latent class modelling’ door onderzoekers niet vaak gebruikt wordt, zou hij veel meer toepassingsgebieden kunnen vinden dan vandaag de dag het geval is. Denk maar aan het opvolgen van merkers voor tumoren en het voorspellen van herval bij kanker, of het in kaart brengen van de cognitieve afname bij ouderen en het optreden van dementie. De mogelijkheden zijn legio. Via dit onderzoek wordt deze techniek onder de aandacht gebracht en wordt aangetoond dat hij uitermate geschikt is voor het maken van voorspellingen. Bovendien kunnen artsen op basis van deze voorspellingen tijdig ingrijpen wanneer nodig en, wie weet, toekomstige levens een kans geven.







